Lecture 6: Simple and LSTM RNNs
강의 목차
- RNN Language Model
- Other uses of RNNs
- Exploding and Vanishing Gradients
- LSTMs
- Bidirectional and mulit-layer RNNs(~lec 7)
1. RNN Language Model

RNN의 기본구조는 다음과 같다.
Big corpus(거대한 말뭉치)가 있을 때, 우리는 긴 단어 sequence를 가져온다. 이를 x1,x2,...xn형태로 word embeddig을 해서 벡터화 시킨다. 그 후, 이를 RNN input으로 사용하는데, 각 단어의 hidden state 즉, 출력은 해당 위치까지의 prefix subsequence를 사용한다.(그 단어 이전까지만 사용)
그다음에는 마지막 단어의 hidden state를 기반으로 모델을 평가해서 update를 해주게 된다.
Language model은 다음 단어를 예측하는 모델이므로, loss function으로는 cross-entropy loss를 사용해 준다.
실제 정답 label인 big corpus는 우리가 가지고 있으므로, 이를 이용해 학습에 사용해준다.
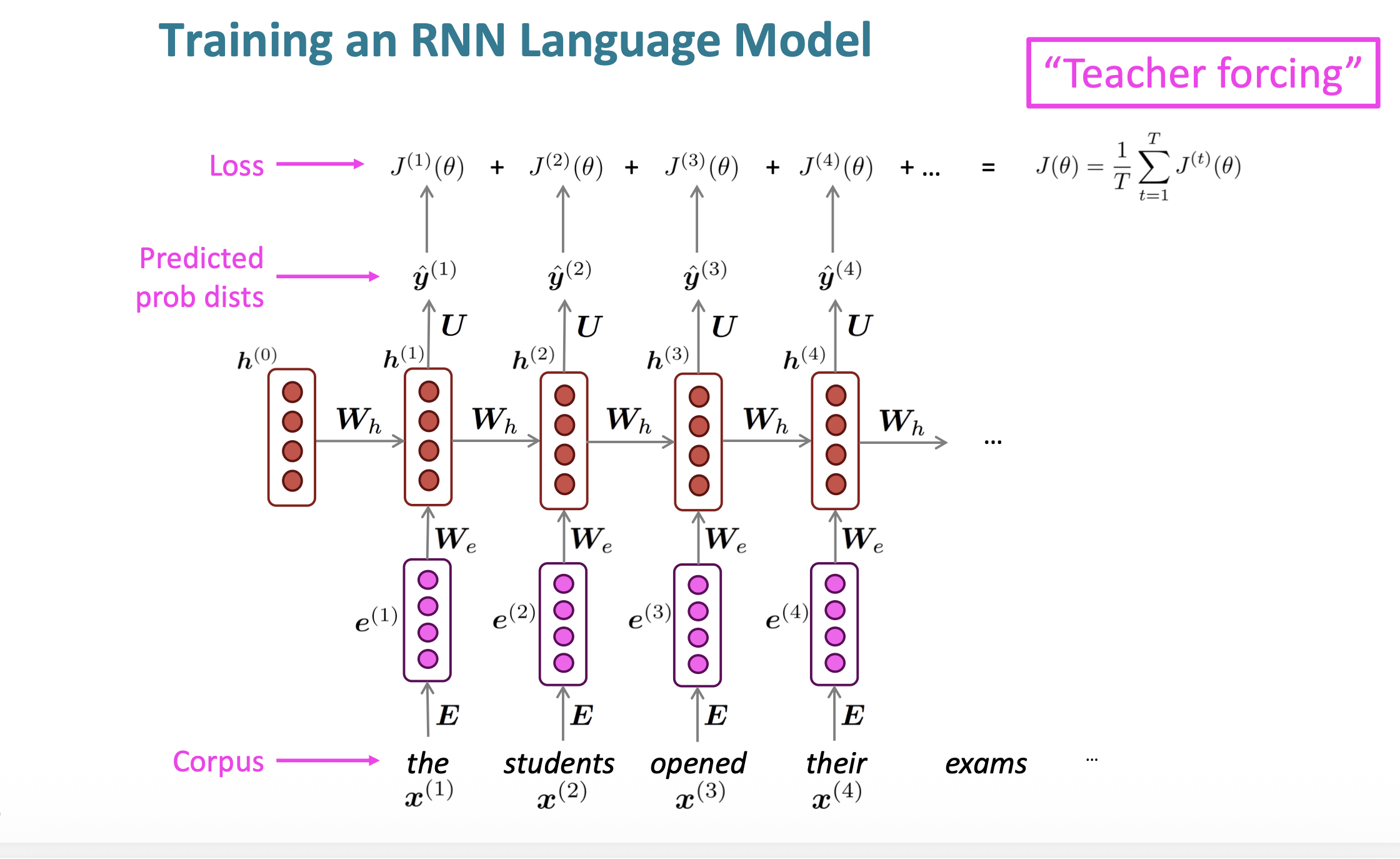
이때, 위의 사진과 같이 각 단어에 대한 loss를 구할 수 있는데, 이를 모두 합한 후 평균을 내어, 'Teacher Forcing'에 사용한다.
'Teacher Forcing'이란, 학습 시 모델이 예측한 단어 대신 실제 정답 단어를 다음 입력으로 강제로 사용하는 기법이다.
즉, target문장이 'The students opened their'에서 다음 단어를 예측해야 될 때, 우리는 The에서부터 시작한다.
그러나, 우리의 모델이 잘못된 방향으로 문장을 이어나갈 수 도 있다.
모델이 현재 예측한 문장이 'The students closed ?'이라도 closed의 다음 단어는 closed를 사용하지 않고, 실제 정답인 'opened'로 학습을 이어간다. 즉, 모델이 잘못 예측한 것이 반영되는 것을 막기 위해, 정답만을 사용하는 것이다.
cf) 이러한 차이를 학습하는 방법으로, '강화 학습'이라는 것도 존재하는데, 이는 위에서의 예측 차이를 고려해서 모델을 업데이트해주는 복잡한 방식인데, 신경망 모델 훈련에서는 굳이 이렇게 복잡하게 할 필요는 없다.
단순하게 한 시점 앞만 예측하는 방식이다. 틀리더라도 다음 단어는 실제 정답지를 바탕으로 train을 이어간다.
실제로는 이렇게 문장 단위가 아니라, 더 작은 단위로 나누어서, mini-batch형태로 병렬 처리를 하는 것이 더 효율적이라고 한다.
예를 들어, 한문단이 있다면, 32개의 mini-batch로 나누어서 32개의 part를 독립적으로 병렬처리를 하는 것이다.
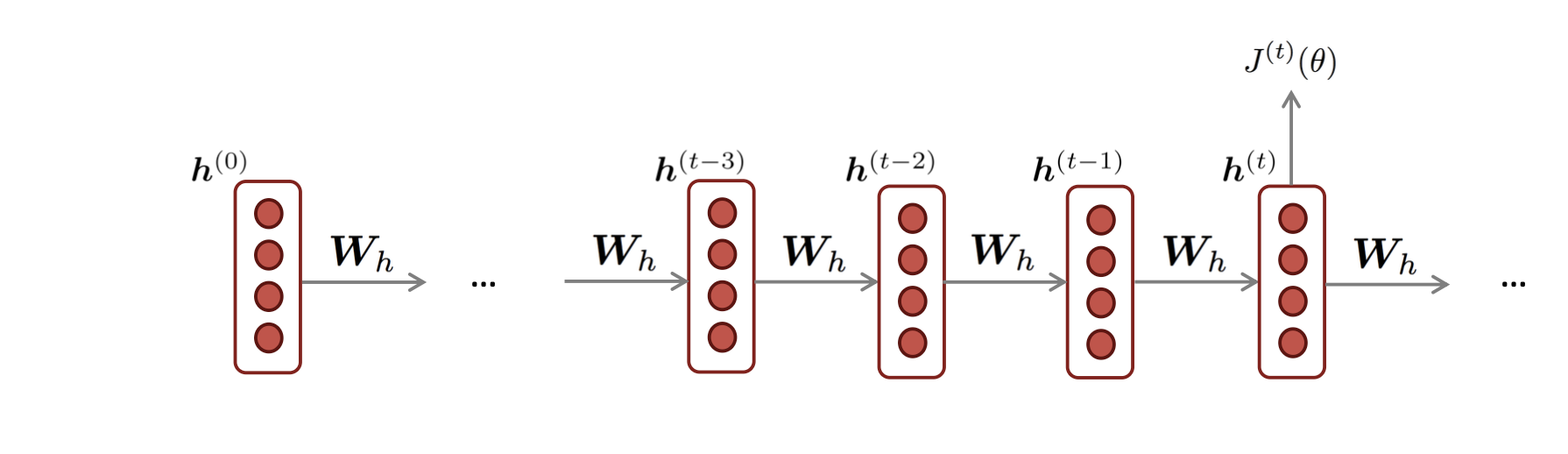
이제 RNN의 backpropagation을 알아보자.
RNN은 위와 같이 sequential 하게 구성되어 있으므로, loss function의 미분형태는 다음과 같다.
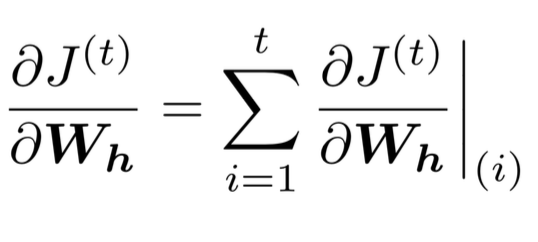

Chain Rule를 사용해서 식을 풀어쓰면, 위와 같은 식이 펼쳐지고, W_h(i)는 모든 i에 대해서 공동 가중치 행렬인 W_h에 해당한다. 따라서, 모든 자기 자신에 대한 미분값이므로 모두 1이 된다.
이때, backpropagation과정에서 주의할 점 2가지
- W_h에 대한 업데이트는 시점마다 따로 계산되지만, 적용은 한 번에 해야 한다. 즉, 각 step에서 구한 gradient를 모아 두었다가, 모든 시점의 gradient를 합산한 뒤 최종적으로 한 번만 W_h를 업데이트해야 한다. (W_h는 모든 시점에서 공유되는 파라미터이므로, 중간에 바로 수정하면 안 된다.)
- Truncated Backpropagation. 문장단위보다 sequence가 길어질 경우, gradinet는 너무 멀리 전파해야 된다. 따라서, 계산 속도가 느려질 수 있으므로, 20과 같은 일정한 길이를 정해두고, 역전파를 20 step까지만 수행. 20만큼만 update 하고 나머지는 무시한다. 이는 효율과 안정성을 위한 것이기 때문에, 정학도는 낮을 수 있다.
RNN의 backpropagation은 backpropagation through time(BPTT)라고 하는데 이는, RNN학습에서 loss를 시간축으로 전개해서, 과거 모든 시점에 gradient를 전달하는 방식이다.
RNN의 generating은 초기 hidden state는 일반적으로 0 vector로 시작한다.
시작 단어가 없을 경우, <BOS> token을 사용하는데(begin of sentence), 이 token도 단어와 동일하게 word embedding을 가진다.
똑같이, 문장의 마지막에도 문장의 종료를 나타내는 <EOS> token이 존재한다.(end of sentence)
<BOS>를 RNN input으로 사용해, softmax 분포에서 sampling을 하여 알맞은 단어를 선택한다. 그 후, 선택된 단어를 RNN에 넣는 과정을 반복하는데, <EOS>가 생성되면 문장생성이 종료되게 된다.
-Evaluating Language Models
RNN의 구조와 메커니즘을 알아봤으니, 평가하는 방식을 알아보자.
RNN을 포함한 Language model을 평가하는 evaluation metric은 'perplexity'라고 한다.

perplexity는 문장의 전체 확률(단어가 x_1부터 x_t까지 주어졌을 때, 다음 단어 x_t+1가 나올 확률)의 역수로 정의하는데, 값이 작을수록 모델이 예측을 잘한다는 뜻이다.
1이면 완벽한 것이고, 10이라면 10개의 단어들 중에서 헷갈렸다는 의미이다.
perplexity는 모델을 훈련한 train data가 아니라 새로운 test data로 평가하게 된다.
또한, perplexity는 cross-entropy함수를 지수화한 형태를 띠는 것을 볼 수 있다.
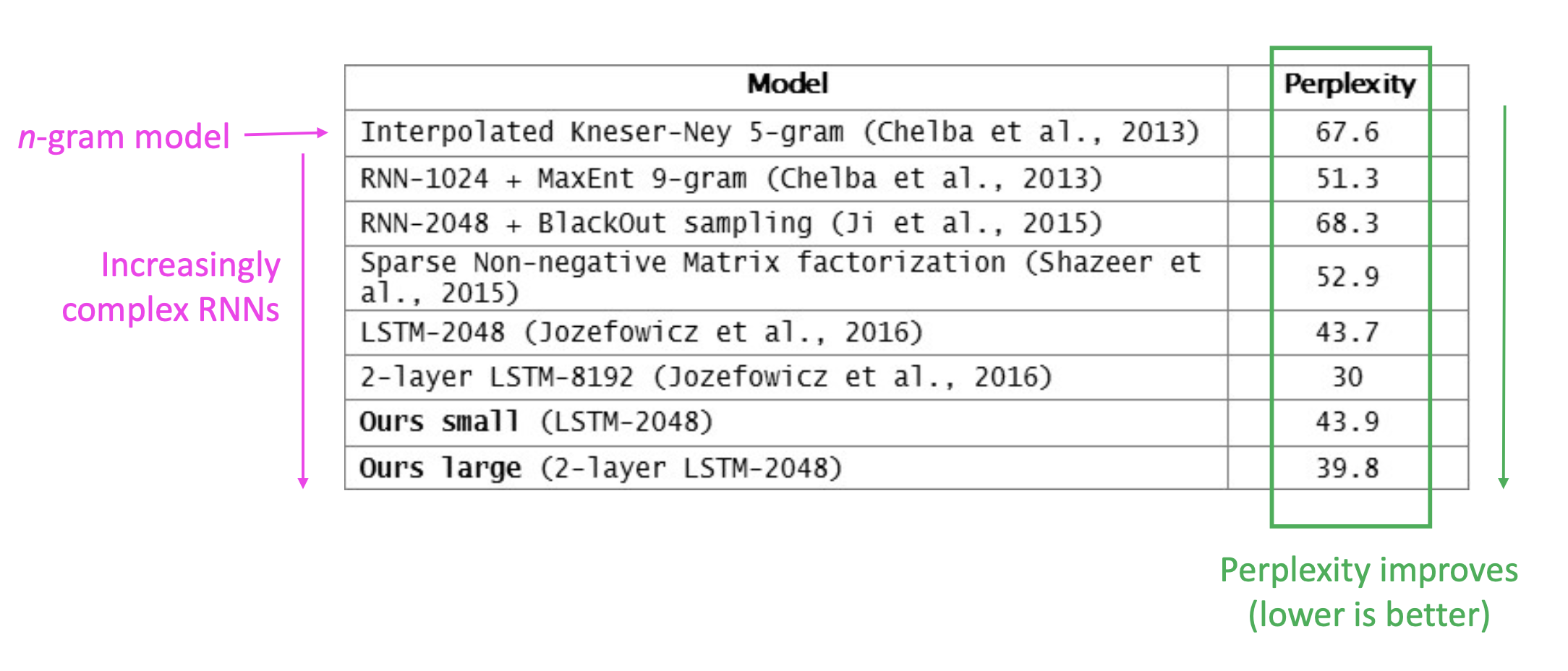
위의 표는 다양한 모델의 perplexity를 보여주는데, n-gram model이 가장 높고, RNN이 가장 낮아, 성능은 RNN이 가장 좋은 것을 알 수 있다.
2. Other uses of RNN
Language Modeling(언어 모델링)은 단순히 다음 단어를 맞히는 과제가 아니라, 언어 이해 능력을 평가할 수 있는 대표적인 benchmark task이자 다양한 NLP 응용의 핵심 subcomponent.
언어모델은 텍스트를 생성하거나 확률을 추정하는 능력을 기반으로 자동완성, 음성·필기체 인식, 맞춤법/문법 교정, 저자 식별, 기계 번역, 요약, 대화 시스템 등 여러 작업에서 중심적인 역할을 한다. 따라서 LM 성능은 곧 NLP 전반의 성능 향상으로 이어지며, 언어 기반 AI 발전의 토대가 된다.
Language Model은 주어진 문맥에서 다음 단어를 예측하는 시스템이고, RNN은 순차적 입력을 처리하며 각 단계마다 같은 가중치를 적용하는 신경망 구조이다. RNN은 LM을 구현하는 데 효과적인 도구이지만, 두 개념은 동일한 것은 아니다.
즉 , RNN은 언어 모델을 만들 수 있는 방법 중 하나일 뿐이며, 음성인식, 시계열 분석 등 다양한 작업에서 활용된다.
이제 RNN의 다양한 사용처에 대해서 알아보자.
- Sequence Tagging
- Sentiment Classification
- Language Encoder Module
- Language Decoder Module
-Sequence Tagging
이는, 다음 단어를 예측하는데 그치지 않고, sequence의 tagging을 하는 task이다. 예를 들어, part-of-speech tagging, NER 등이 해당된다.
-Sentiment Classification
감정 분석은 문장 전체에 대한 분석을 하는 행위로, 다음 문장이 positive인지 negativie인지 파악하는 과정이다. 문장 전체를 RNN에 통과시키다 보면, 마지막 hidden state가 sentiment result가 되는데, 이는 문장 정보가 마지막 hidden state에 누적되기 때문이다.
더 좋은 방식은, 모든 단어의 hidden state를 다 사용하는 것인데, max/ eman pooling을 사용해서 정보를 통합시킨다. 이러한 방식은 소실되는 RNN정보를 방지할 수 있다.
-Language Encoder Module
questioning answering, machine translation과 같이 문장을 encoding 해야 해는 Task에도 도움이 된다.
RNN -> hidden states -> state -> 문장 vector 이러한 단계의 마지막 문장 vector로 encoding을 하면 문장 전체의 내용이 하나의 문장 벡터로 변환되기 때문에, QA와 같은 task에 효과가 좋다.
-Language Decoder Module(generate)
speech recognition, mahcine translation, summarization과 같은 task가 이에 해당한다.
speech recognition일 경우, 음성을 RNN의 input으로 사용해서, speech로부터 text를 생성할 수 있다. (multimodal??)
이러한 방식을 'conditional language model'이라 하는데, 이는 speech에 의존하기 때문이다. machine translation도 문장에 의존하기 때문에 이에 속한다.
3. Exploding and Vanishing Gradients
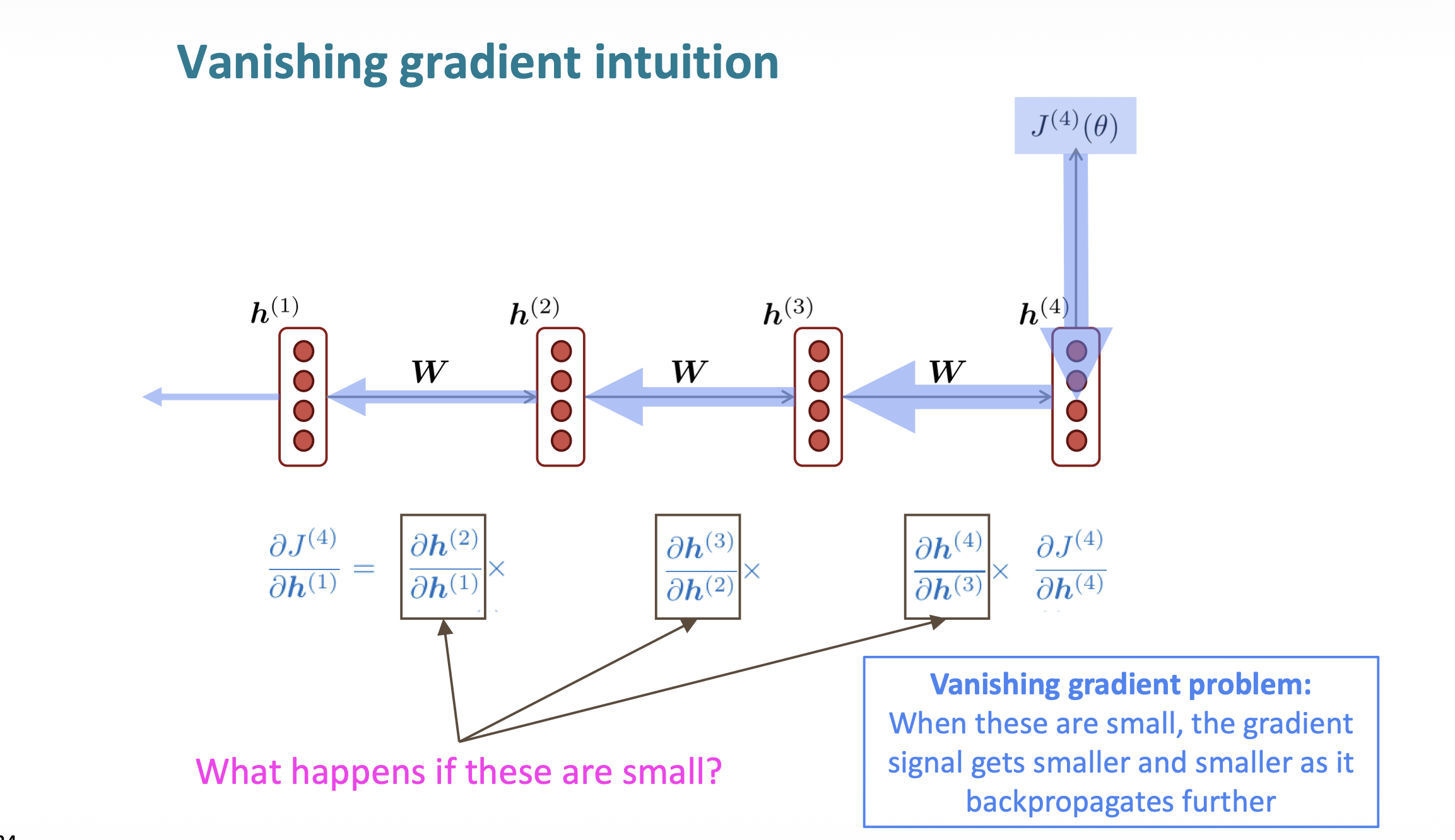
RNN의 구조상 Loss function을 미분할 때, sequence가 길어지면, chain rule 또한 길어진다.
이때, 곱셈의 증가 때문에 문제가 생기게 되는데, 이때 gradient를 살펴보면 다음과 같은 형태를 가진다.
이 gradient는 0~1 사이의 값을 가지고, 이 곱셈이 길어지면 값들은 지수적으로 0에 가까워지게 된다.
따라서, sequence가 길어질수록 gradient가 급격히 줄어들게 된다. 자세한 것은 아래의 증명을 통해 확인하자.

계산의 편의를 위해 non-linear function은 x로 정의하고, 계산을 해보면, W_h의 l승이 남게 되는데, 이를 eigen value분석을 해보자.
(W_h는 hidden state의 가중치 행렬로 모든 state에서 동일)

이런 식으로, W_h를 eigen decomposition 분해하면, 람다값에 의존하게 되는데, 람다값이 1보다 작으면 w_h의 l승은 0으로 수렴하게 된다. 따라서, 시간이 지날수록 값들이 점점 소실도히는 것이다..
(람다값은 보통 tanh, sigmoid 이러한 함수를 사용하기 때문에, [0,1) 범위에 있음. 또한, 임의로 1보다 큰 값을 사용하면 반대로 exploding gradient으로 치우쳐서 또 다른 문제 발생.
exploding gradient의 문제점은, gradient update step이 너무 커져서 정상적인 최소점 방향으로 이동하지 않고, 엉뚱한 지점으로 튀어버린다. 최악의 경우, 수치적으로 INF, NAN발생. )
-> 즉 RNN의 vanishing/exploding problem은 이러한 람다값이 크기에 영향을 받는 것이 아니라, 근본적으로 체인룰을 사용해서 곱셈의 형태로 미분값이 전개되는 것이 본질적 문제이다.
뒤에서 설명하지만, 이러한 곱셈의 형태를 사용하지 않는 방향으로 대체 모델들이 나오게 되고 , 그중에서 우리가 알아볼 예정이 LSTM이다.
이렇게 vanishing gradient 때문에, 거리가 먼 내용은 덜 반영되고, 가까운 것은 많이 반영되는 문제가 발생한다.
**Exploding Gradient의 한 가지 해결책은 'gradient clipping'이 존재한다.
gradient clipping은 not for vanishing gradient.
오직, gradient가 과하게 커지는 경우를 방지해 주는 방식으로, 값이 너무 클 경우, Update에 적용시키기 전에, 그 값을 threshold와 비교해 주는 것이다. 그 threshold보다 클 경우, 이를 일정 수준으로 잘라내서(clip) 안정성을 유지하는 방법이다.

이렇게 chain rule의 길어지는 곱셈연산 때문에 생기는 2가지 문제를 살펴보았다.
exploidng은 clipping이라는 해결책이 존재해서 기술적으로 크게 문제가 되지 않는다. (실무에서도 clipping으로 거의 다 제어 가능)
그러나, vasnishing을 그렇지 않다.
Vanisihig이 근본적인 RNN의 난제이다.
그래서 사람들이 이를 보완해서 새로운 다양한 방식들을 개발했는데, 그중 이번 강의에서 소개할 방식이 바로
LSTM(Long Short Term Memory)이다.
4. LSTMs
LSTM은 RNN의 한 종류로 Hochreiter와 Schmidhuber에 의해 1997년 처음 개발되었다. (97년도 논문보다 지금 많이 사용하는 LSTM은 2000년도 논문이니 이걸 참고하자)
만들어진 이유는 앞에서도 계속 강조한 gradient vanishing을 해결하기 위해서였다.
그럼 LSTM의 구조를 한번 자세히 살펴보자.
RNN에서는 sequence의 순서와 정보를 담기 위해 한 가지의 hidden state를 사용하였다면, LSTM에서는 두 개의 state, hidden and cell state가 존재한다.
hidden state는 현시점에서 필요한 정보(short-term)를 담고 있고, cell state에는 long-term정보를 저장하여, 일종의 pc의 memory처럼 설계되었다.
따라서, LSTM의 구조는 하나의 cell state와 3개의 gate로 이루어진 hidden state가 다음과 같이 존재한다.
- Forget Gate (망각 게이트)
- 이전 cell state에서 어떤 정보를 버릴지 남길지 결정.
- $f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)$
- Input Gate (입력 게이트)
- 현재 입력에서 어떤 정보를 cell state에 새로 추가할지 결정.
- $i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)$
- 후보 cell state:
- $\tilde{C}t = \tanh(W_c [h{t-1}, x_t] + b_c)$
- Output Gate (출력 게이트)
- 최종 hidden state를 어떻게 출력할지 결정.
- $o_t = \sigma(W_o [h_{t-1}, x_t] + b_o)$
- 새로운 hidden state:
- $h_t = o_t \cdot \tanh(C_t)$
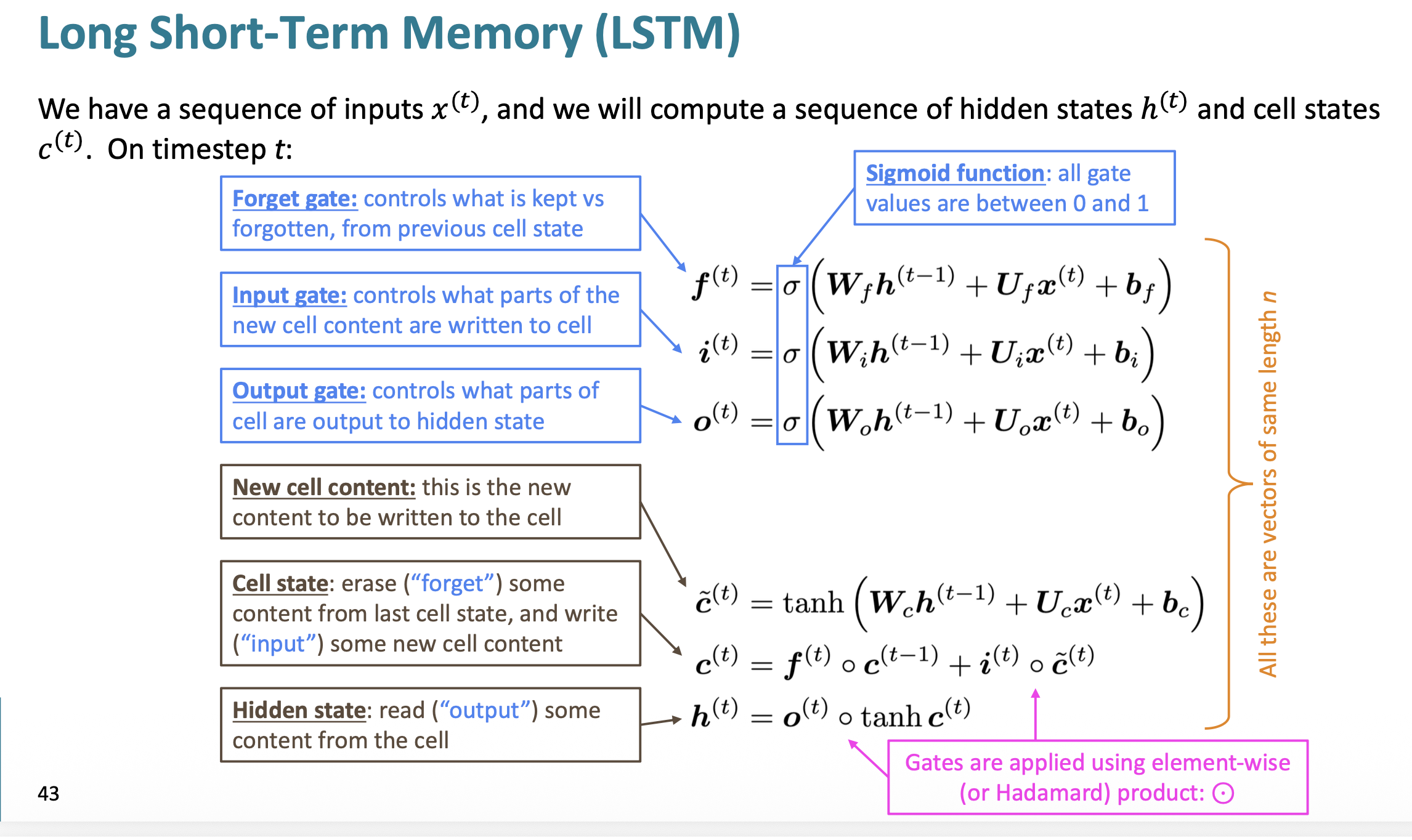
모든 게이트들은 sigmoid함수를 사용해서, 출력이 0~1 사이이고, 이는 얼마나 게이트를 열고 닫을지 비율을 조정하는 것이다.

LSTM의 흐름은 다음과 같다.
- 현재 입력, $x_t$, 이전 Hidden state $h_{t-1}$, 이전 cell state $c_{t-1}$가 들어온다.
- $x_t$와 $h_{t-1}$를 받아 sigmoid연산을 하여 $f_t$를 출력하는데 이는 forget gate에 해당하는 값으로, 이전 cell staet $c_y$를 얼마나 기억/잊을지를 결정한다.
- input gate $i_t$와 $ \tilde{c}_t$를 곱해서 새로 추가할 정보"를 결정한다.
- $c_t = f_t \cdot c_{t-1} + i_t \cdot \tilde{c}_t$ cell state를 update 해준다. 여기서 +가 핵심!!
- 최종 hidden state는 cell state의 tanh(c)를 꺼내와 $o_t$와 곱해 결정한다.
여기서 + 덕분에 RNN의 chain rule multiplication에서 벗어나 과거 값들이 소실되지 않는 LSTM을 구현할 수 있었던 것이다.
이름 그대로 long and short-term, 즉 긴 시퀀스의 정보도 유지할 수 있고, 동시에 매 시점의 hidden state정보도 short term으로 처리하는 신경망을 구현한 것!!
하지만, 이러한 LSTM이 vanishing을 완벽히 극복해 낸 것은 아니다. vanila rnn에 비해 좋다는 것이지 이런 문제가 발생하지 않는 것을 보장해주는 것은 아니다. 그 이유는 forget gate는 초기에는 보통 1로 설정해서 모든 정보를 보존해준다. 그러나 스텝이 길어짐에 따라, forget gate는 1보다 작은 값을 사용하게 되고 정보를 손실하게 된다.
즉, LSTM은 vanishing을 완벽히 극복해낸 모델이라기보다는, vanishing을 조절해 줄 수 있는 모델이라고 해야 옳은 표현이다.
그렇다면, vasnishing problem은 RNN만의 문제일까??
--> 아니다. 깊이가 있는 모든 neural network의 문제점이다. ex) feed forward convolutional NN
그러나, RNN의 고정된 weight matrix 때문에 처음 대두된 것이다. ( rnn은 시간축으로 weight가 공유되는데, 한 층을 수백, 수천번 반복한 것과 같은 효과가 나타난다. ex) 100길이 sequence like 100 layers of nn)
따라서, 다른 nn에서도 이러한 문제점을 해결하기 위해서 추가적인 Direct connection을 추가해서 gradient를 잘 흐르게 해 줬는데, 이의 한 예시가 바로 'ResNet'이다.

'ResNet' (Residual Connection)은 위와 같이, 추가 경로를 만들어줘서 y = F(x) + x 구조가 된다.
resnet은 기본 형태인 F(x)에 identity항 x를 추가적으로 더해준다.
만약 기본형태만 사용할 경우 gradient는 F'(x)이 전해질텐데, 만약 층수가 깊어질 경우, F'(x)가 사라지는 vanishing문제가 발생한다. 따라서, F'(x)가 0이 되어 계산이 멈춰버리는데, 여기에 x를 추가한다면, gradient는 F'(x) + I (identity)로 F'(x)가 없더라도 최소한의 계산은 identity로 인해 다음 층으로 넘어갈 수 있게 된다.
즉, 최소한의 gradient보장 덕분에 학습이 끊기지 않는 것이다.
하지만, I가 있더라도, 다음과 같은 문제점이 발생할 수 있다.
- F(x) + x가 너무 커지면 gradient explosion의 가능성. (발산)
- optimization 어려움.
- Representation Bottleneck : 모든 걸 항등으로만 흘려보내면 네트워크가 '아무 일도 안 하는 블록'처럼 되어버릴 수 있음.
따라서, 다양한 방식들이 추가적으로 생겼는데
"DenseNet" : 아예 모든 층을 직접 연결해서 정보 손실 최소화
"Highway Network" : 게이트를 도입해 어떤 경로를 통과할지 학습. (resnet과 동일하지만, x를 더해주는 여부를 gate로 조절)
간단하게 이런 것들이 있다는 점만 확인하고 넘어가자.

5. Bidirectional and multi-layer RNNs( ~ Lec 7)
이 부분은 lec7강의로 이어진다.
간단히 설명하자면, 우리는 지금까지 단방향 sequence를 다루었다.
즉, 문장이 있다면, 시작부터 끝 방향으로만 문장을 입력받았다.
그러나, 인간의 문장은 오직 앞(왼쪽)에서만 영향/의존하는 것이 아니라, 문장 전체의 단어에 영향을 받는 것이 일반적이다.
따라서, 양방향 sequence에 대한 처리가 필요하다.
bidirectional rnn은 이를 처리한 모델로, 순방향 rnn과 역방향 rnn을 각각 계산해 주고, 이를 합친 결과를 사용해 주는 것이다.

'LLM' 카테고리의 다른 글
| Stanford CS224N Lec9 (Winter 2021) (0) | 2025.10.06 |
|---|---|
| Stanford CS224N Lec7 (Winter 2021) (0) | 2025.09.29 |
| Stanford CS224N Lec5 (Winter 2021) (0) | 2025.09.15 |
| Stanford CS224N Lec4 (Winter 2021) (0) | 2025.09.03 |
| Stanford CS224N Lec3 (Winter 2021) (0) | 2025.09.03 |
