Lecture 9 : Pretraining
강의 목차
- A brief note on Subword Modeling
- Motivating model pretraining from word embeddings
- Model Pretraining three ways
- Decoders
- Encoders
- Encoder - Decoders
- What do we think pretraining is teaching?
1. A brief note on Subword Modeling
이전강의들에서 알아본 word vector모델들은 (ex.word2vec) 유일한 finite한 단어 집합 vocabulary를 가정했다. 즉 데이터를 보고 어던 단어들을 사전에 넣을지 정한 뒤, 그 단어들로만 'word embedding'을 학습하였다.
하지만 여기서 발생하는 문제는 변형어나 신조어들이다. 'taaaaasty'나 'transformerify'와 같이 새로운 단어를 만들면 인간은 쉽게 이해하고 사용가능하지만 모델은 vocab에 없는 부분이라 받아들일 수가 없다.
하지만 언어는 늘 이런 방식으로 새로운 단어를 만들어내고, 특히 새로운 분야나 젊은 세대에서는 신조어가 끊임없이 등장한다.
**cf)이러한 단어를 새로 만들어내는 법칙을 연구하는 분야를 'derivational morphology'(파생형태론)이라고 한다.
이러한 변형된 단어들은 그 의미가 데이터에 기반하여 보면 충분히 잘 정의되어 있음에도 불구하고, 기존의 단어 집합에는 매핑되어 있지 않다. 그렇다면 어떻게 해야 할까?
과거에는 이러한 경우를 **범용적인 미지의 토큰(unknown token, UNK)**으로 매핑하곤 했다.
즉, 모델이 전혀 본 적이 없는 무언가를 만나면 항상 동일한 UNK 토큰으로 표현해버리는 것이다.
그러나 이 방식은 많은 정보를 완전히 잃어버린다는 점에서 바람직하지 않다.
그렇다고 전혀 매핑하지 않을 수는 없으므로, 어쩔 수 없이 UNK라는 단일 표현으로 처리해야 했던 것이다.
단어의 변형된 형태를 모두 독립적인 단어 벡터로 처리하기에는, 서로 의미가 유사한데 따로 처리하는 것은 효율성 및 학습 측면에서 옳지 않은 방식이다.
그래서 우리가 최종적으로 하게 되는 것은 서브워드 구조(subword structure), 즉 서브워드 모델링을 살펴보는 일이다.
우리가 취할 방식은 더 이상 모든 단어 집합을 정의하려고 하지 않고, 대신 **단어의 일부(부분 단어, subword)**들을 어휘집에 포함시키는 것이다.
다시 말해, 단어를 이미 알고 있는 서브워드들의 연속으로 분할하는 것이다.
이를 위한 간단한 알고리즘이 있다.
우선 모든 문자를 어휘로 시작한다고 가정하자.
예를 들어, 내가 가진 어휘가 모든 문자와 “단어의 끝(end-of-word)” 기호뿐이라고 하자. 그러면 유한한 데이터셋 안에서, 내가 미래에 어떤 단어를 보더라도, 모든 가능한 문자를 이미 가지고 있는 한 그 단어를 각 개별 문자들의 연속으로 분해할 수 있다.
이렇게 하면 UNK 문제는 발생하지 않는다. 즉, 어떤 단어든 일정한 방식으로 표현할 수 있게 되는 것이다.
(가장 간단하고 기본적인 방식은 character 단위로 나누어서 다루는 것!!)
예시
- 단어: “transformerify”
- 문자 단위로 분해: [t, r, a, n, s, f, o, r, m, e, r, i, f, y]
- 따라서 이 단어를 본 적 없어도 표현할 수 있다.
그 다음에는, 자주 함께 등장하는 문자들을 찾아서 “a”와 “b”가 자주 같이 나타난다면, 이를 새로운 단어로 어휘집에 추가한다고 하자.
이제 어휘에는 개별 문자들뿐 아니라 “ab”라는 새로운 서브워드도 포함된다.
이렇게 문자 쌍을 새로운 서브워드로 치환하고, 또다시 반복하면서, 자주 함께 나타나는 문자 조합들을 점점 많이 어휘에 추가하게 된다.
결국 이렇게 해서 만들어지는 것은 **자주 등장하는 부분 문자열(substring)**들로 구성된 어휘이며, 이를 통해 단어를 조립할 수 있다.
이러한 접근법은 원래 기계 번역(machine translation)에서 처음 개발되었으나, 현재는 거의 모든 현대 언어 모델에서 광범위하게 사용된다.
예를 들어, “hat”이나 “learn” 같은 단어는 충분히 자주 등장하기 때문에 서브워드 어휘에서 각각 독립적인 단어로 포함된다. 이는 원하는 결과이다. 하지만 “tasty” 같은 단어는 “T-A-A”, “A-A-A”, “S-T-Y”와 같이 서브워드 단위로 나누어질 수 있다.
이때 일부 토큰화 시스템에서는 앞에 ## 기호를 붙여서 “이 앞에는 공백을 추가하지 말라”는 표시를 하기도 한다.
즉, 하나의 단어처럼 보이는 “tasty”가 실제 모델의 어휘에서는 세 개의 서브워드 토큰으로 나뉘는 것이다.
이를 Transformer나 RNN에 입력한다고 하면, RNN은 “T-A-A”를 하나의 입력으로 받아 업데이트를 수행하고, 그다음 “A-A-A”를 입력받아 다시 업데이트를 하고, 마지막으로 “S-T-Y”를 입력받아 업데이트를 하게 된다.
따라서 모델은 이러한 분해된 단어 구조를 처리할 수 있게 된다.
이 방식은 원래 전체 단어 “tasty”를 보았을 때 의미를 알 수 없었던 문제를 해결한다.
예를 들어, 중간에 “A-A-A”를 더 추가한 변형이 오더라도 비슷하게 처리할 수 있다.
“transformerify”도 마찬가지이다. “transformer”는 독립된 단어로 어휘에 포함되고, “-ify”는 별도의 서브워드로 포함된다.
이렇게 하면 UNK 하나로 모든 것을 뭉뚱그리지 않고, 세 개의 학습된 임베딩으로 표현할 수 있다.
이는 매우 유용하며, 사실상 모든 현대 NLP에서 변형된 알고리즘들이 사용되고 있다.
이렇게 하나의 단어를 여러개의 subword로 분리하게 된다면, 최종 의미는 어떻게 구하게 될까?
예를 들어, 'taaaaasty'를 세개의 임베딩으로 나누어 표현할 때, 'TAA', 'AAA',' STY'를 독립적인 토큰으로 다룬다. 이러한 3개의 벡터를 평균낼 수 도 있고, 마지막 토큰 만 사용할 수도 있고 다양한 방식으로 상황에 맞게 처리하게 된다.

2. Motivating Model Pretraining from Word Embeddings
You shall know a word by the company it keeps(J.R.Firth 1957:11)
.. the complete meaning of a word is always contextual, and no study of meaning apart from a complete context can be taken seriously(J. R. Firth 1935)
위의 distributional hypothesis의 핵심 idea를 담고있는 구절에 따르면, 단어의 완전한 의미는 항상 문맥적(contextual)이며, 문맥을 완전히 고려하지 않은 의미 연구는 진지하게 받아들일 수 없다.
Word2Vec에서는 단어의 의미가 주변 문맥에 의해 어느 정도 반영되지만,“record”처럼 문맥에 따라 ‘기록하다(동사)’ 또는 ‘기록, 음반(명사)’처럼 여러 의미를 가지는 단어를 하나의 벡터로 표현하기 때문에,이 모든 의미를 완벽히 구분해내지는 못한다.
이러한 한계를 극복하기 위해 등장한 것이 바로 'Contextual Embedding'(문맥적 임베딩) 이다.

기존의 word embedding만 pretrained(사전 학습)하고 각 task에 맞는 학습은 따로 하는 방식이다.
즉, 단어 벡터는 미리 학습했지만, 문맥은 따로 학습하였다.
word2vec, GloVe와 같은 static 단어 임베딩을 사용했고 문맥적 관계는 LSTM이나 Transformer를 학습하면서 새로 배워야 했다.
즉 문맥정보는 모델이 task(downstream)에서 새로 배웠어야만 했다.
이러한 방식에는 다음과 같은 문제점이 존재한다.
- downstream task 데이터가 충분히 커야 한다. 즉, 문맥적 의미를 스스로 배우려면 많은 데이터가 필요하다.
- 대부분의 네트워크 파라미터는 랜덤 초기화 된다. 즉, 고정된 단어 임베딩을 제외하고 각 task마다 모두 처음부터 다시 배워야 하기에 문맥적인 내용은 모든 task마다 초기화된다.

위의 문제점을 해결하기 위해서,
2017년 단어 수준 임베딩 시대에서 2018년 이후 Pretraining whole models(모델 전체 사전학습) 시대로 패러다임이 전환되었다.
과거에는 단어 임베딩만 사전학습했지만, 이제는 모델의 거의 모든 파라미터가 사전학습으로 초기화된다.
즉, BERT나 GPT처럼 네트워크 전체가 이미 대규모 말뭉치에서 학습되어 있는다. 따라서, downstream task에서는 fine-tuning(미세 조정)만 하면 된다.
이러한 방식의 장점은 다음과 같다.
- 단어/문장/문맥 수준의 언어 표현을 훨씬 풍부하게 학습한다.
- 모델 전체가 이미 언어를 이해하고 있기 때문에, downstream task에서 적은 데이터로도 빠르게 수렴 가능하다.(속도,효율 증가)
- GPT처럼, "다음 단어 확률 분포"를 모델링함으로써 텍스트 생성능력까지 확보한다.
그렇다면 사전학습은 어떤 식으로 진행될까??
사전학습의 핵심 아이디어는 'masked language modeling', 즉 가려진 단어의 복원 이다.
문맥으로부터 언어의 구조를 추론하도록 만들기 위해, 모델이 정답(가려진 단어)를 맞히게 하는 것이고, 이를 위해 단어 간의 문법적 관계와 의미적 패턴을 스스로 학습할 수 있어야 한다.
💡 예를 들어,
“Stanford University is located in ___.”
이 문장에서 빈칸을 맞출려면,
- “Stanford University”가 **지명(대학)**이라는 사실
- “is located in”이라는 표현 뒤에는 지역명이 온다는 통계적 규칙
- “Palo Alto”나 “California”처럼 현실 세계 지식(world knowledge) 도 함께 필요
“I put ___ fork down on the table.”
이 문장은 문법 학습의 예시로, 언어의 구조를 스스로 이해하는 과정이다.
➡️ 즉, 언어적 지식 + 문법 규칙 + 세계 지식을 모두 통합적으로 학습하게 되는 것이다.
이런 이유로 사전학습은 단순히 “빈칸 채우기”가 아니라,
**인간의 언어 이해 과정을 모사한 자기지도학습(Self-supervised Learning)**이라고 볼 수 있다.
즉 정리하자면, 사전학습(pretraining)은 언어를 '모사 학습' 하는 과정이다. 모델은 단순히 단어를 맞히는 수준이 아니라 언어의 의미론.통사론적 규칙을 내면화하낟. 이러한 pretraining은 fine-tuning의 토대가 되어 모델이 적은 데이터로도 고성능을 발휘할 수 있게 한다.
결과적으로 현대의 nlp 모델(BERT, GPT, T5)은 단어를 넘어서 문맥, 문장, 세계지식 까지 학습하는 시스템이 된 것이다.'
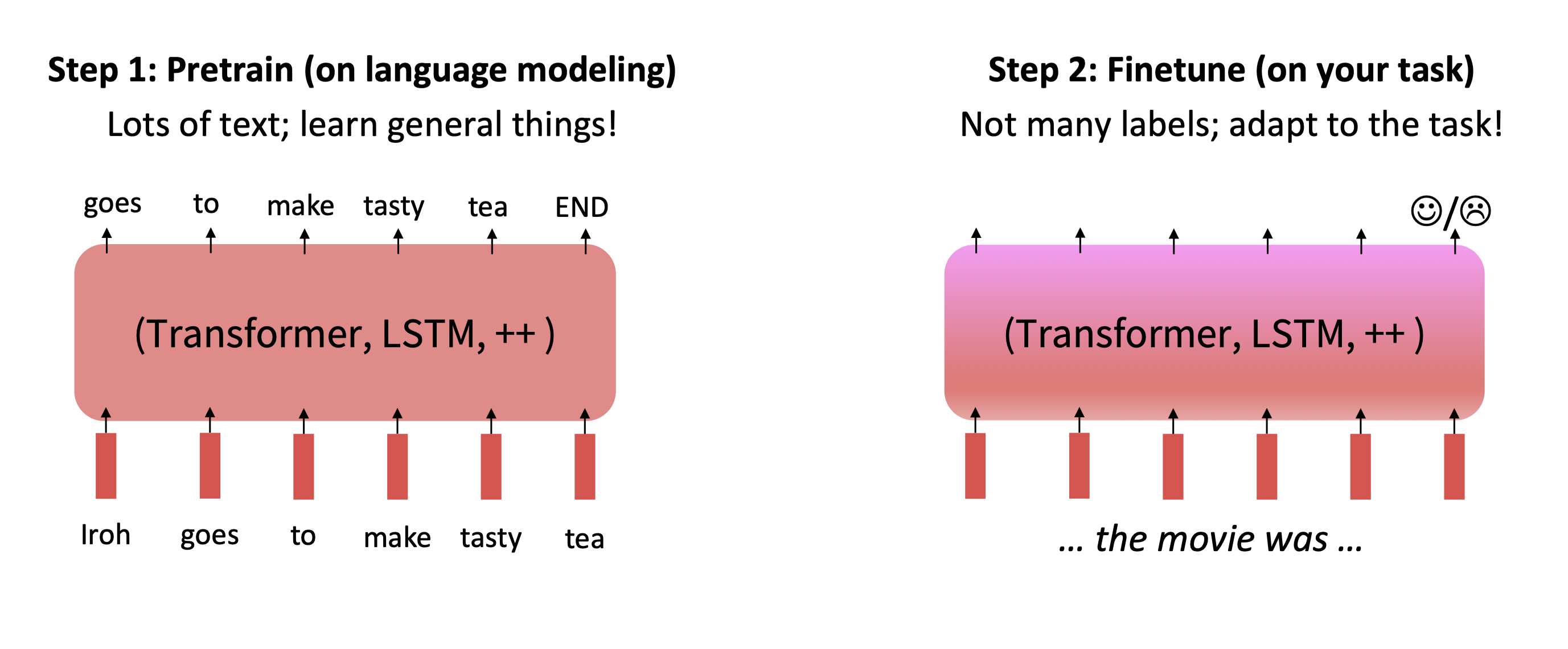
수학적으로도 왜 pretraining - finetuning 구조가 도움이 되는지 알아보자.
사실 아직 완전히 규명된 연구 주제(oepn area of research, 즉 이론적으로 완변히 설명된 것은 아니지만 직관(intuition)을 이해하고 넘어가자.
우선, pretraining은 모델의 파리미터 θ 에 대한 좋은 초기 값, 즉 시작점 θ̂ 을 제공한다.
사전학습은 이렇게 정의된 손실 함수를 최소하 하는 과정이다.
$ \min_{\theta} L_{\text{pretrain}}(\theta)$
즉, θ̂ 는 언어 구조, 문법, 의미, 분포 등을 잘 반영한 좋은 초기값(initialization) 이 됩니다.
그 다음, finetuning 단계에서는 우리는 task data와 label을 이용해, 해당 작업의 손실 함수를 최소화 하도록,
$\min_{\theta} L_{\text{finetune}}(\theta)$
를 풀게 된다.
하지만, 여기서 중요한 점은 —
우리가 **gradient descent(경사하강법)**을 수행할 때,
- *완전히 무작위 초기값(random initialization)**에서 시작하는 게 아니라
이미 사전학습으로 얻은 θ̂에서 시작한다는 것이다.
이론적으로는 “시작점이 달라도 결국 전역 최적점(global minimum)에 수렴한다면
상관없어야 할 것처럼 느껴지지만,”
실제로는 시작점이 엄청나게 중요하다.
현실에서 gradient descent는 θ̂ 근처에서 시작해서 **그 주변의 좋은 지역(local minimum)**으로 빠르게 수렴한다.
즉,
- 사전학습으로 이미 “언어적 지식이 잘 반영된” 좋은 파라미터 근처에서 시작하기 때문에
- fine-tuning 과정은 훨씬 짧고 안정적으로 “좋은 골짜기(valley)”에 도달한다는 것이다.
이건 실험적으로도, 실무적으로도 효과가 확실한데,
그 이유를 최적화(optimizaton) 연구자들이 여전히 수학적으로 탐구하고 있는 중이다
3. Model Pretraining three ways
pretraining에는 크게 3종류의 구조가 존재한다.
- Encoders
- Encoder-Decoders
- Decoders
1. Encoders
encoder는 양방향을 볼 수 있는 구조라, encoder 그 자체로는 다음 단어를 예측하는 언어모델링은 불가능하다. 미래를 보고 대답하는 것은 너무 trival 하기 때문이다.
따라서, 추가 작업을 하게 되는데, 바로 'masking'이다.
ex)
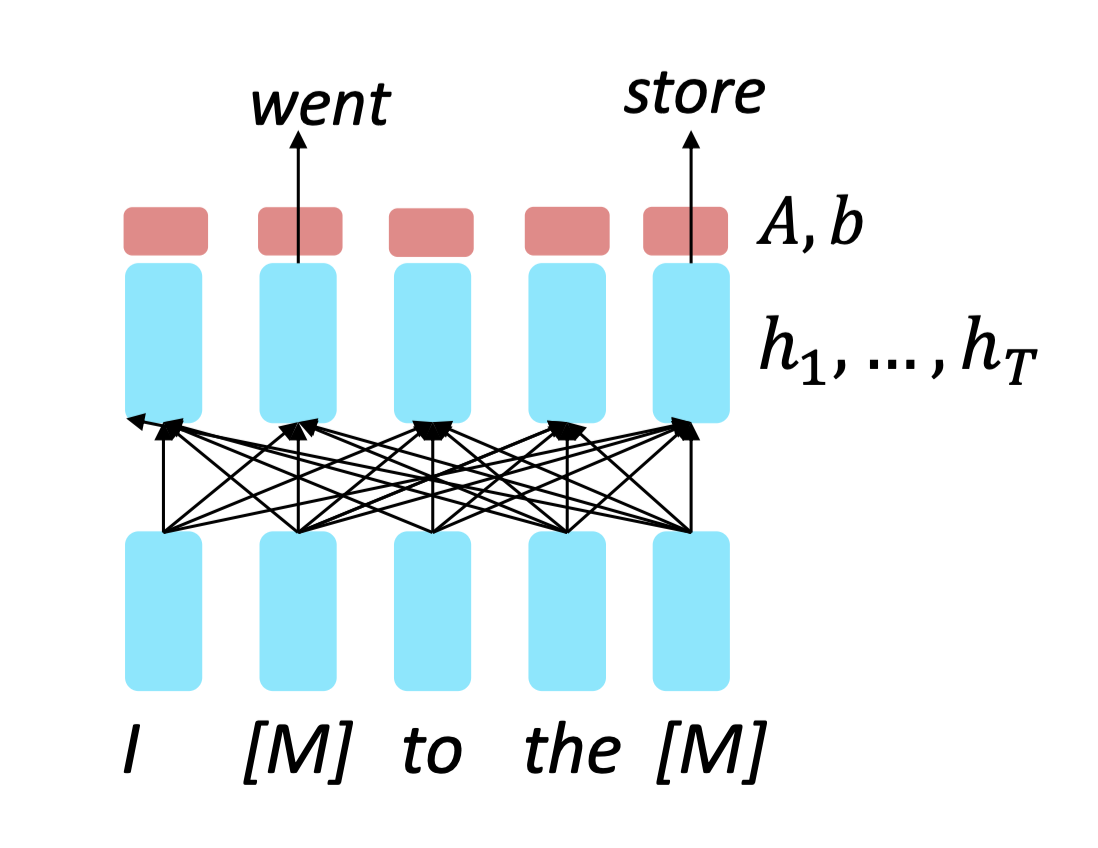
I went to the strore -> I [M] to the [M] 로 masking. 모델은 M을 제외한 문맥을 보고 mask를 예측하게 하는 방식.
따라서 손실(loss)을 계산할 때는,
문장 전체 단어가 아니라
- 가려진 단어들(masked words)**에 대해서만 손실을 계산한다.
즉, 오직 그 단어들에 대해서만 예측 → 손실 계산 → 역전파(backpropagation) 과정을 수행한다.
수학적으로 보면, 이는 단순히 “문장 전체 x의 확률 P(x)”를 학습하는 것이 아니라 “**손상된 문장 x~ (x tilde)**가 주어졌을 때, 원래 문장 x의 확률 P(x | x~)”을 학습하는 것과 같다.
여기서 x~는 masking된 corrupted문장이다.
이 과정을 통해 Encoder는
각 단어마다 하나의 출력 벡터(파란색)를 생성한다.
이 벡터는 문맥 정보를 모두 반영한 contextual representation이다.
이때 masking은 랜덤하게 선택된다.
-BERT
(Bidirectional Encoder Representations from Transformers)
Google에서 만든 대표적인 encoder BERT의 masked language modeling를 통해 구체적으로 어떻게 동작하는지 살펴보자.
BERT의 pretraining에서는 전체 입력 토큰 중 **무작위로 약 15%**를 masking해서 예측하도록 학습을 한다.
이 때, 기준은 단어가 아니라 subword이다.
subword는 앞에서 설명드린 내용으로, 단어를 유의미한 자주 사용하는 단위로 쪼개서 사용하는 것이다.
ex) Input Sentences : "I'm playing soccer."
Subwords : ["I", "'m", "play", "##ing", "soccer", "."]
masking : I'm [Mask] ##ing soccer.
이렇게 완전한 단어 단위 대신, subword단위를 사용하면 새로운 단어, 철자 오류, 복합어 등을 더 잘 처리할 수 있다는 장점이 있다. 훨신 더 유연하고 일반화가 잘된다.
이제 이런식으로 15%의 subword를 masking한다고 했는데, 여기서 몇가지 다른 추가 처리를 해줄 것이다.
다음의 3가지 경우로 나누어서 처리를 한다.
- 80% : [MASK]로 교체 ex)"I went to the [MASK]"
- 10% : 랜덤한 단어로 교체. ex) "I went to the pizza" (store -> pizza)
- 10% : 변경하지 않음. ex) "I went to the store" (하지만 정답은 여전히 예측해야 함)
이 방식의 직관(intuition)은 다음과 같다.
만약 내가 단지 [MASK]가 된 단어들만 복원하는 방식으로 학습시킨다면,
모델은 [MASK]라는 특수한 토큰이 등장할 때만 작동하는 모델이 되어버릴 것이다.
하지만 실제로 우리가 이 모델을 **테스트(추론)**할 때, (fine tuning)
예를 들어 영화 리뷰 감정 분석(sentiment analysis)을 할 때,
그 입력에는 [MASK] 같은 토큰이 전혀 존재하지 않는다.
따라서 모델이 “진짜 단어 입력 환경”에서도 잘 작동하게 만들기 위해,
일부는 랜덤하게 바꾸거나, 일부는 아예 그대로 두는 전략을 섞는 것이다.
가끔은 모델이 이런 생각을 할 수도 있다.
“음, 이번 입력 문장에는 [MASK]가 하나도 없네. 그럼 내가 할 일이 없잖아.”
즉, 모델이 [MASK] 토큰에 대해서만 예측을 수행하도록 학습되면,
실제 문장(마스크가 없는 입력)을 만났을 때는
“이건 내가 할 일이 아닌데?” 하고 제대로 작동하지 못할 수도 있다는 것이다.
그래서 우리는 모델이 항상 **모든 단어를 문맥 속에서 잘 표현(represent)**하도록 만들고자 한다.
모델은 마스크가 전혀 없는 문장이라도
각 단어의 **문맥적 표현(contextual representation)**을 잘 형성할 수 있다.
즉, BERT는 단지 [MASK]를 복원하는 데에만 능한 게 아니라,
문장 전체를 이해하고 표현할 수 있는 **언어 표현 모델(language representation model)**로 발전하게 된다.

그리고 BERT의 또 다른 특별한 점은 segment embedding을 알아보자.
BER에서는 subword를 의미하는 'token embedding'과 문장내에서 위치를 의미하는 'position embedding'이외에도 추가적으로 'segment embedding'을 사용한다.
segment embedding은 subword가 A,B중 어느 문장에 속하는지에 대한 정보를 가지고 있다.
이 3가지 임베딩을 합쳐서 최종 입력 벡터로 사용하게 된다.
이러한 이유는, BERT는 입력으로 한 번에 두개의 문장(또는 문단 일부)을 입력으로 처리하는 경우가 있기 때문이다.
이는 BERT에서 NSP학습을 가능하게 해준다.
NSP는 next sentence prediction으로 두 문장(A, B)을 입력받았을 때, B가 실제로 A 다음에 오는 문장인지, 아니면 무작위로 가져온 문장인지를 예측하는 과제이다.
즉. 모델이 문장간의 논리적 연결관계를 이해할 수 있도록 훈련시키는 과정이다.
즉 **BERT는 Masked Language Modeling과 Segment Embedding을 통해 문장 내부의 의미적 관계뿐 아니라 문장 간의 관계까지 모델에 효과적으로 학습시킬 수 있다. 이후에는 fine-tuning 을 통해 감정 분석, 문장 분류, 문답, 추론 등 다양한 다운스트림 태스크에 맞게 모데을 변형하여 사용할 수 있다.

BERT 문장 분석 성능은 매우 좋은 것을 알 수 있다.
BERT가 등장하기 전, 즉 **사전학습(pretraining)**이 보편화되기 이전의 시절을 떠올려보자.
그때는 NLP 연구자들이 각자 맡은 과제마다 완전히 다른 신경망 구조를 직접 설계하곤 했다.
예를 들어, 감정 분석 모델을 만들 때는 CNN 기반 구조를,
기계 번역 모델은 RNN 기반 구조를,
질의응답 모델은 또 다른 attention 구조를
각자 “이게 최선일 것 같다”는 방식으로 따로따로 설계했다.
즉, 모든 과제마다 별도의 신경망 아키텍처, 손실 함수, 연결 구조, 가중치 초기화 방식 등을
연구자들이 직접 고안해야 했다.
그래서 태스크 하나당 모델 하나, 완전히 제각각이었다.
하지만 BERT가 등장하면서 이 모든 것이 완전히 뒤집혔다.
“거대한 Transformer 하나를 만든 다음,
문장에서 단어를 가려놓고 복원하게만 학습시킨 뒤,
각 과제에 맞게 약간만 미세조정(fine-tuning)하면 된다.”
이 간단한 아이디어 하나로,
이전까지 태스크마다 따로 모델을 설계하던 시대가 완전히 사라졌다.
그야말로 **패러다임 전환(sea change)**이었다.
연구자들은 충격을 받았고,
NLP 전체가 “하나의 사전학습된 모델이 거의 모든 과제에 통한다”는 사실을 처음으로 경험했다.
물론, BERT는 지금의 ChatGPT처럼 대화형으로 화려하지는 않았지만,
오늘날의 LLM(대규모 언어 모델) 혁명은 바로 이 BERT에서 시작되었다.
BERT는 “모든 NLP 문제를 하나의 공통 프레임워크 안에서 해결할 수 있다”는
새로운 시대의 문을 연 결정적 계기였다.
- 그렇다면 BERT는 단점이 없을까? 이렇게 잘 된다면, 그냥 모든 곳에 쓰면 되는 거 아닌가??
그런데 답은 "그럴 수 없다" 이다.
그 이유는 **BERT의 사전학습 목표(pretraining objective)**가 어떤 구조를 가지고 있느냐 때문이다.
BERT는 문장의 일부를 가려놓고 그 단어를 맞히는(masked language modeling) 과제로 학습되었기 때문에,
즉 빈칸 채우기(fill-in-the-blank) 문제에는 매우 강하다.
하지만 이런 구조는 텍스트를 실제로 ‘생성(generate)’하는 문제에는 적합하지 않다.
예를 들어,
문서 요약(summary)을 생성하거나,
새로운 문장을 만들어내는 일에서는
BERT는 자연스럽게 다음 단어를 예측하는 구조가 아니기 때문에 잘 작동하지 않는다.
BERT는 “이전 단어들이 주어졌을 때 다음 단어를 생성”하는 모델이 아니다.
대신 양방향으로 문맥을 본 상태에서 가운데 단어를 복원하는 모델이다.
따라서 문서를 분류하거나, 특정 토픽을 예측하거나, 텍스트가 유해한지 아닌지를 판단하는 일에는 매우 좋지만,
새로운 문장을 생성하거나 요약을 만들어내는 일에는 적합하지 않다.
-마지막으로 BERT의 extension, 즉 확장된 버전에 대해 이야기해보자.
위에서 마스킹은 랜덤하게 한다고 하였는데, 사실 단순히 무작위로 토큰을 마스킹하는 것보다 더 좋은 방법이 있다.
바로 연속된 구간(span) 전체를 마스킹하는 것이다.
왜냐하면, 일반적인 랜덤 마스킹 방식은 맞추기가 너무 쉽기 때문이다.
예를 들어, 문장의 일부를 보면, “irresistibly”라는 단어의 일부분이 가려졌을 때,
앞뒤 subword 조각(예: “irresist” + “##ibly”)만 봐도 정답을 너무 쉽게 추측할 수 있다.
반면, 더 긴 연속 구간(span) 을 마스킹하면, 예측 난이도가 높아지고
모델이 더 풍부한 문맥을 학습해야 하므로 결과적으로 더 좋은 성능을 낸다.
즉, 단 하나의 subword만 가리는 것보다, 그 단어를 구성하는 모든 subword를 함께 가리면
훨씬 더 도전적인(그리고 유용한) 학습이 된다.”

2. Encoders - Decoders
이제 인코더-디코더(encoder-decoder) 모델을 보자.
여기서도 언어모델링(language modeling)과 비슷한 것을 할 수 있다.
입력 시퀀스(input sequence)가 있고, 인코더의 출력 시퀀스(output sequence)가 있다.
이 중 앞부분을 양방향 문맥(bidirectional context)을 위한 prefix 로 보고,
나머지 뒷부분 단어들을 예측하도록 설정할 수 있다. (prefix는 예측안함)

즉, 일반적인 언어모델처럼 동작하게 하는 것이다.
이를 구현하는 한 가지 방법은, 긴 텍스트를 두 부분으로 나눈 뒤,
앞부분을 인코더에 입력하고, 뒷부분은 디코더가 생성하도록 하는 것이다.
이 방법도 잘 작동하긴 하지만,
실제로는 Span Corruption 이라는 개념이 훨씬 더 잘 작동한다.
Span Corruption은 T5(Text-to-Text Transfer Transformer)의 핵심 학습 목표로, 입력 문장에서 연속된 단어 구간(span)들을 제거하고, 그 자리에 고유한 토큰 <X>,<Y>.. 을 넣는다. 그리고 디코더는 지워진 구간들을 순서대로 복원하도록 학습한다.
예를 들어, "Thank you <X> me to your party <Y> week 가 input sentence가 있다고 하자. 그럼 다음 출력 단계에서는, 그 마스크 토큰 과 그 자리에 들어가야 할 원래의 단어들을 생성한다.
즉, 출력은 다음과 같이 된다:
“Thank you” 다음에 “–for inviting–” 을 예측하고,
그 뒤에 “–me to your party last week–” 를 생성한다.
이런 식으로 하면,
모델이 문장을 예측할 때 양방향 문맥(bidirectional context) 을 사용할 수 있게 된다.”
✅ 이 구조는 BERT의 Masked LM과 유사하지만,
단일 단어가 아니라 “연속된 구간(span)” 을 예측하며,
그 예측을 생성(decoding) 형태로 수행한다는 점이 다릅니다.
이러한 모델에는 흥미로운 특성이 발견되었다.

사실, T5에서는 'Salient Span Masking'(SSM)으로 발전된 기법을 사용한다. 랜덤하게 span masking하는 것이 아니라, 중요한 구간만 골라서 마스킹 하는 기법이다. 여기서 중요하다는 것은 의미적으로 중요한 구간을 의미한다.
예를 들어 “Franklin D. Roosevelt was born in ___” 같은 문장을 보고,
빈칸에 들어갈 부분을 생성하도록 훈련되었다.
Open-Domain Question Answering (ODQA) 라는 과제가 있다.
여기에는 “Franklin D. Roosevelt는 언제 태어났는가?” 같은 퀴즈형 질문이 포함되어 있다.
이때 모델은 외부 데이터베이스를 참조하지 않고,
오직 학습된 파라미터(parameter) 안에 저장된 지식으로부터
문자열 형태의 답을 직접 생성해야 한다.
흥미로운 점은, 이런 Salient Span Masking으로 사전학습한 뒤
소량의 질의응답(QA) 데이터로 미세조정(fine-tuning) 하면,
모델이 처음 보는 새로운 질문에도 올바른 답을 생성할 수 있었다는 것이다.
즉, 모델이 사전학습 중 습득한 잠재적 지식(latent knowledge) 을
스스로 “인출(retrieve)” 하는 것처럼 보였다.
물론 정확도는 50% 미만이었지만, 무작위 추측(random guessing) 보다 훨씬 높았다.
이는 매우 흥미로운 현상이다.
모델이 사전학습을 통해 암묵적으로 저장해 둔 지식에 접근(access) 하게 된 것이다.
즉, 단순히 “When was Roosevelt born?” 같은 문장을 주면
모델이 답변을 생성할 수 있게 된다.
하지만 중요한 점은, 언어적으로 매우 자연스럽게 들리지만
사실적으로는 틀린 경우가 많다는 것이다.
이 특성은 ChatGPT 같은 최신 모델에서도 여전히 관찰된다. (hallucination problem)
3. Decoders
다음은 Decoder-only 구조(GPT류) 모델에 대한 설명이다.
여기서는 각 단어가 자신보다 앞의 단어들만 참고하여 다음 단어를 예측한다.
이런 모델은 예를 들어 감정 분석(sentiment analysis) 같은 과제에서
마지막 토큰의 은닉 상태(hidden state) 를 문장 표현으로 활용해
미세조정할 수 있다.
또는 앞서 언급한 것처럼 파라미터 효율적 튜닝(parameter-efficient fine-tuning)
기법을 적용할 수도 있다.
강력한 모델들은 디코더인 경향이 있다.
인-디코더 구조보다 간단하고, 모든 매개변수를 하나의 큰 네트워크(decoder only)에서 공유할 수 있다.
decoder로 가장 유명한 GPT계열을 알아보자.
우선 GPT-1이다.
transformer의 decoder구조만을 사용해서, '이전 단어들을 보고 다음 단어를 예측'하는 언어모델로 사전학습되었다.
gpt1에서 자연어 추론(Natural Language Inference, NLI) 같은 작업을 하고 싶다고 해보자.
이 과제는 문장 쌍을 입력으로 받아,
예를 들어 “그 남자는 문간에 서 있다(The man is in the doorway)” 와
“그 사람은 문 근처에 있다(The person is near the door)”
이 두 문장을 보고 첫 번째 문장이 두 번째 문장을 함의(entail) 하는지를 판단하는 것이다.
즉, 첫 번째 문장이 사실이라면 두 번째 문장도 사실이라고 믿을 수 있는가를 예측한다.
이럴 때 모델은 단순히 두 문장을 하나로 연결(concatenate) 하면 된다.
즉, 시작 토큰을 넣고, 첫 번째 문장을 입력한 뒤,
중간에 구분자 토큰(delimiter, 예: [SEP])을 넣고,
그 뒤에 두 번째 문장을 입력한다.
그 다음에는 모델이 “entailment(함의)”인지, “not entailment(비함의)”인지
예/아니오(yes/no)로 분류하도록 훈련한다.
[START] The man is in the doorway [DELIM] The person is near the door [EXTRACT]
이러한 방식(예: 자연어 추론 등)으로 GPT를 미세조정(fine-tuning) 했을 때 꽤 좋은 성능을 냈다.
그 후 등장한 BERT는 양방향 문맥(bidirectional context) 을 활용할 수 있었기 때문에
조금 더 나은 성능을 보였지만, GPT 역시 매우 우수한 결과를 냈다.
그 다음으로 등장한 것이 GPT-2
이후 등장한 GPT-2는 네트워크의 생성 능력(generative ability) 에 초점을 맞췄다.
모델 크기를 1억 1700만 → 15억 개 파라미터로 대폭 확장했고,
간단한 프롬프트(prompt) 를 주면 놀라울 정도로 일관된 문장을 이어 쓸 수 있었다.
(예: 과학자와 유니콘에 대한 이야기처럼 자연스러운 서사 생성)
당시 이 정도 크기의 모델은 여전히 단일 GPU에서도 미세조정이 가능했으며,
긴 문장을 논리적으로 이어가는 능력이 매우 인상적이었다.
또한 학습 데이터도 약 90억 단어 규모로 크게 늘어났다.
그 다음은 GPT-3
그 다음 등장한 GPT-3는 언어모델과의 새로운 상호작용 방식을 제시했다.
그 전까지 우리는 사전학습된 모델을 두 가지 방식으로만 사용했다:
- 모델이 정의한 확률 분포에서 샘플링(sampling) 하여 텍스트를 생성 (예: 번역)
- 특정 과제에 맞춰 미세조정(fine-tuning)
그런데 GPT-3는 놀랍게도 아무런 추가 학습 (fine tuning) 없이도
일부 과제를 수행할 수 있는 새로운 능력을 보였다.
GPT-3는 GPT-2보다 훨씬 거대했다.
파라미터 수가 15억 → 1750억 개로 늘었고,
약 3000억 단어의 방대한 텍스트로 학습되었다.
이때 새롭게 발견된 능력이 바로 In-Context Learning(문맥 내 학습) 이다.
이는 모델이 입력에 주어진 예시만 보고,
그 패턴을 스스로 이해하고 확장하는 능력을 의미한다.
예를 들어, 입력으로
thanks → merci
hello → bonjour
를 주면, 모델은 문맥 속 패턴을 파악해
“goodbye → au revoir”와 같이
비슷한 방식으로 번역을 추론하고 생성할 수 있다.
이것이 바로 “창발적 특성(emergent properties)” 이라는 개념의 시작이었다.
즉, 모델이 충분히 커졌을 때만 나타나는 새로운 능력들이 존재한다는 것이다.
작은 모델을 봤을 때는 이런 질적으로 다른(new qualitative) 행동이
등장할 것이라고 전혀 예상할 수 없었다.
이는 단순히 언어 모델링(language modeling) 신호만으로는
도저히 예상할 수 없는 현상이다.
GPT-3는 오직 디코더(decoder) 로만 학습되었고,
그저 “다음 단어를 예측(next word prediction)”하도록 훈련되었을 뿐이다.
그런데도 놀랍게도, 그 학습만으로 모델은
문맥(context) 에 따라 꽤 복잡한 작업을 수행할 수 있게 되었다.
지금까지 우리는 단어의 의미나 문맥(context)을 반영한
좋은 표현(good representations)에 대해 이야기해왔다.
그런데 GPT-3는 단순히 이런 문맥적 표현(contextual representation) 을 넘어,
새로운 수준의 능력을 보여준다.
이건 매우 고수준의 패턴 매칭이다.
모델은 단지 입력된 데이터, 즉 한 시퀀스의 텍스트 내에서
패턴을 찾아내고 그것을 어떻게 이어가야 할지를 학습한다.
이런 모델이 무엇을 해결할 수 있고, 어디까지 가능한지, 한계는 무엇인지는
현재도 여전히 열린 연구 주제(open question) 다.
예를 들어, GPT-3는 학습 중에 수많은 이중언어 사전 데이터를 봤을지도 모른다.
그래서 번역처럼 보이는 작업을 하는 건
그저 “많이 본 패턴을 복원하는 것”일 수도 있다.
혹은 정말로 문맥 안에서 새로운 작업을 학습하는 것일 수도 있다.
정확히 어느 쪽인지는 확실하지 않지만, 두 성질이 섞여 있는 중간 형태로 보인다
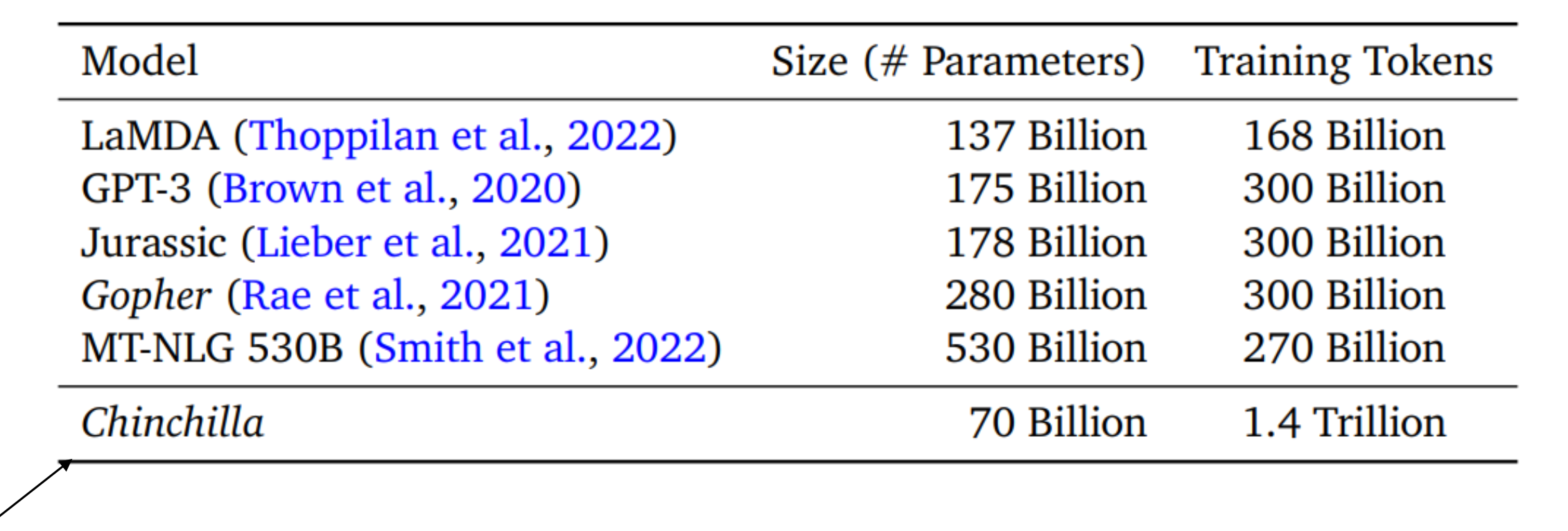
GPT-3는 비효율적으로 큰 모델이었다.
GPT-3는 1750억 개 파라미터, 3000억 단어로 학습되었고,
그 규모의 모델을 훈련시키는 데에는 막대한 비용이 든다.
그럼 과연 모델 크키와 데이터크기를 어떻게 조합해야 가장 효율적일까?
이러한 질문에 DeepMind연구진들의 결과는 다음과 같았다.
No
Deepmind 연구가들의 Chinchilla모델을 살펴보자.
그들은 GPT-3보다 절반 크기(70B 정도) 의 모델 Chinchilla 를 만들었는데,
훨씬 더 많은 데이터로 학습시키자 오히려 성능이 더 좋았다.
일종의 tradeoff.
-Chain of Thought
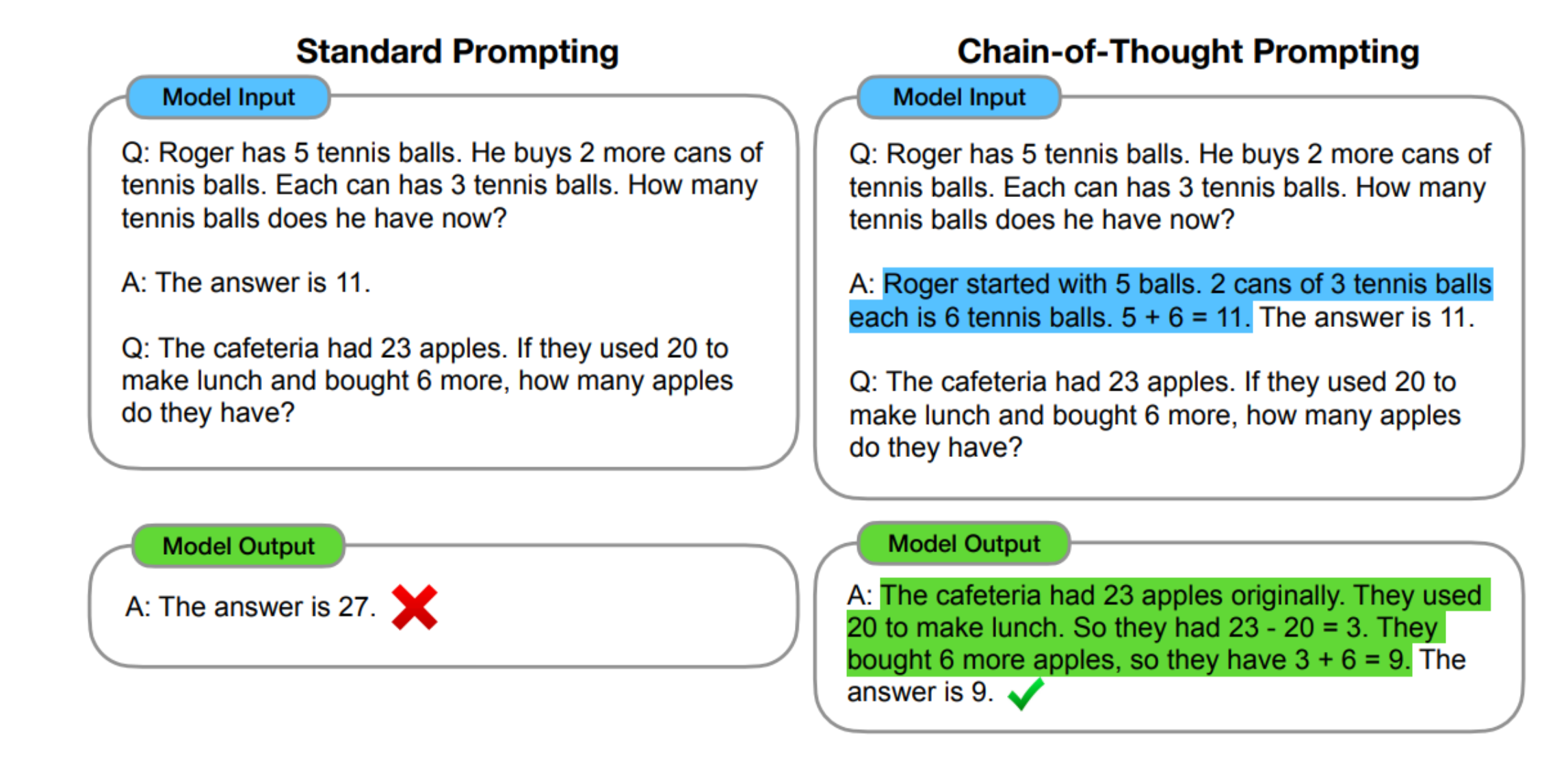
최근에는 모델과의 또 다른 상호작용 방식인 Chain of Thought (사고의 연쇄) 가 등장했다.
보통 우리는 모델에 “질문 → 정답” 쌍만 보여주지만,
그 대신 질문을 푸는 사고 과정(단계별 추론) 을 함께 보여주면
모델이 먼저 중간 단계를 생성하고
그 후에 최종 답을 내는 방식을 스스로 학습한다.
“질문 → 중간추론 → 정답”
형식으로 답을 생성하며,
단순히 바로 답을 내는 것보다
훨씬 높은 정확도를 보인다.
이 방식이 정확히 왜 효과적인지는 아직 명확히 밝혀지지 않았다.
이처럼 거대한 네트워크는 강력하지만 불투명하며, 현재 시점에서 완벽히 파악되지 않은 분야이다.
4. What do we think pretraining is teaching?
pretraining은 모델에게 어떤 능력을 가르칠까??
사전학습된 모델들들은 언어의 통계적 특성에 대해 매우 다양한 것들을 학습한다는 증거가 점점 늘어나고 있다.
① Trivia (상식·사실 지식)
Stanford University is located in ________, California.
→ 정답: Palo Alto
→ 모델은 사실적 지식(factual knowledge) 도 학습함.
(즉, 단어들의 공동 출현(co-occurrence) 통계로부터 사실적 정보를 암묵적으로 습득)
② Syntax (구문론)
I put ___ fork down on the table.
→ 정답: the
→ 문법적 규칙(명사 앞에 관사가 온다 등)을 자동으로 학습함.
이는 “문장 구조(syntax)”를 암묵적으로 이해한다는 의미.
③ Coreference (지시어·참조 관계)
The woman walked across the street, checking for traffic over ___ shoulder.
→ 정답: her
→ 모델은 ‘woman’이 주어이므로 her를 써야 한다는 지시 관계(co-reference) 를 학습함.
④ Lexical semantics / Topic (어휘 의미론 / 주제 관련성)
I went to the ocean to see the fish, turtles, seals, and ____.
→ 정답: dolphins
→ 같은 주제(topic coherence) 내에서 어울리는 단어를 예측하는 능력.
(즉, 바다 생물이라는 의미장(domain)을 파악)
⑤ Sentiment (감정 분석)
Overall, the value I got from the two hours watching it was the sum total of the popcorn and the drink. The movie was ___.
→ 정답: boring / bad
→ 문맥의 정서적 분위기를 이해하고 긍·부정 감정(sentiment) 을 학습.
⑥ Reasoning (추론)
Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the ____.
→ 정답: kitchen
→ 문맥 추론(reasoning)을 통해 ‘Zuko가 있던 장소’ 를 추측함.
→ 단순 통계가 아닌 논리적 관계를 내포.
⑦ Basic arithmetic (기초 수학적 패턴)
I was thinking about the sequence that goes 1, 1, 2, 3, 5, 8, 13, 21, ____.
→ 정답: 34
→ 모델은 수학 공식을 “이해”하진 않지만,
반복되는 패턴을 언어적 통계로서 학습하기는 함.
(단, 피보나치 규칙 자체를 이해하는 건 아님 — 단순 연속성 패턴 추정만 가능)
⑧ Bias (편향)
Models also learn — and can exacerbate racism, sexism, all manner of bad biases.
→ 모델은 인간 언어 데이터를 그대로 학습하므로,
그 안에 포함된 사회적 편견(racism, sexism 등) 도 함께 습득한다.
(즉, 사전학습은 강력하지만 “중립적이지 않음”)
이렇게 다양한 것들을 배우지만, 동시에 모델들은 인종차별, 성차별 등의 사회적 편향(biases)또한 학습하고, 심지어 그것을 강화하기도 한다. 이 주제는 추후에 자세히 다룰 예정.!
'LLM' 카테고리의 다른 글
| Stanford CS224N Lec10 (Winter 2021) (1) | 2025.10.09 |
|---|---|
| Stanford CS224N Lec7 (Winter 2021) (0) | 2025.09.29 |
| Stanford CS224N Lec6 (Winter 2021) (0) | 2025.09.22 |
| Stanford CS224N Lec5 (Winter 2021) (0) | 2025.09.15 |
| Stanford CS224N Lec4 (Winter 2021) (0) | 2025.09.03 |