Lecture 7: Translation, Seq2Seq, Attention
- a new task : Machine Translation
- new neural architecture : sequence to sequence
- new neural technique : Attention (~Lec8)
1. a new task : Machine Translation
Machine Translation(MT)란?
'the task of translating a sentence x from one language(the source language) to a sentence y in another language(the target language)
즉, 우리가 흔히 생각하는 언어간의 번역 작업을 컴퓨터에서 하는 것을 의미한다.

MT의 간단한 역사부터 알아보자.
-Pre-Neural Machine Translation
1950s, 최초의 기계번역은 단순히 사전에서 동일한 의미를 찾아, 단어를 바꿔주는 방식으로 진행되었다.
(냉전시기 러시아어를 영어로 번역하여 우위를 점하기 위해서 영국에서 시작됨.)
너무나 원시적인 방식이라, 복잡한 인간의 언어를 다루기에는 충분치 않았다.
1990s, 규칙 기반의 기계 번역 - Statistical Machine Translation (SMT)
확률적 통계기반 모델로 번역을 시도하였다.
main idea는 다음과 같다.
프랑스어 문장 x가 주어졌을 때, 가장 좋은 영어 문장 y를 찾는 문제가 있다고 가정하자.
$y^* = \arg\max_y P(y|x)$
즉, 이러한 조건부확률의 argmax로 나타낼 수 있다.
직접 위의 식을 구하는 건 어렵기 때문에, 베이즈 규칙을 이용해 분해한다.
$P(y|x) \propto P(x|y)P(y)$
$y^ = \arg\max_y P(x|y) P(y)$
이렇게 두 개의 항으로 나누어지는데,
각각, translation model과 language model이라 정의한다.
- Translation Model (번역 모델) — P(x|y)
- 특정 영어 문장 y가 주어졌을 때, 그것이 프랑스어 문장 x로 번역될 확률.
- 즉, 단어와 구가 어떻게 번역되는지 (충실성, fidelity) 를 학습.
- 병렬 데이터 (parallel corpus) → 같은 의미의 프랑스어-영어 문장 쌍에서 학습.
- Language Model (언어 모델) — P(y)
- 문장이 영어로서 얼마나 자연스럽고 유창한지 (fluency) 를 평가.
- 단일 언어 데이터(monolingual corpus) → 영어 문장들만 모아 학습.
- 확률적 언어모델. 즉, 번역된 단어들을 조합했을 때, 그것이 자연스러운 문장이 되도록 해주는 모델을 의미한다.
P(y)는 앞선 강의에서 구한 언어모델이고, P(y|x)를 다루어야 하는데, 어떻게 translation model P(x|y)를 학습할 수 있을까?
우선, 두 언어로 이루어진 많은 양의 parallel data를 필요로 한다.
그 후, 새로운 변수를 도입하는데, 그것이 바로 alignment변수이다.
alignment변수 'a'는 원문 문장과 번역 문장 사이으이 단어 수준 혹은 구(phrase)수준 대응 관계를 나타내주는데, 즉 두 문장 간 alignment를 유도할 수 있다면, 특정 단어나 짧은 구가 특정 방식으로 번역될 확률을 계산할 수 있다.
예를 들어, 어떤 언어가 주어-동사-목적어(SVO)순서를 따르지만, 다른 언어는 주어-목적어-동사(SOV)나 동사-주어-목적어(VSO)를 취한다면, alignment는 이러한 단어 순서의 차이까지 포착할 수 있다.
또한, 언어가 표현방식을 달리하는 차이도 잡아낼 수 있는데, 실제로 언어 간 단어 대응을 고려하다 보면, 단어가 번역되지 않고 아예 생략되는 경우도 나타난다.
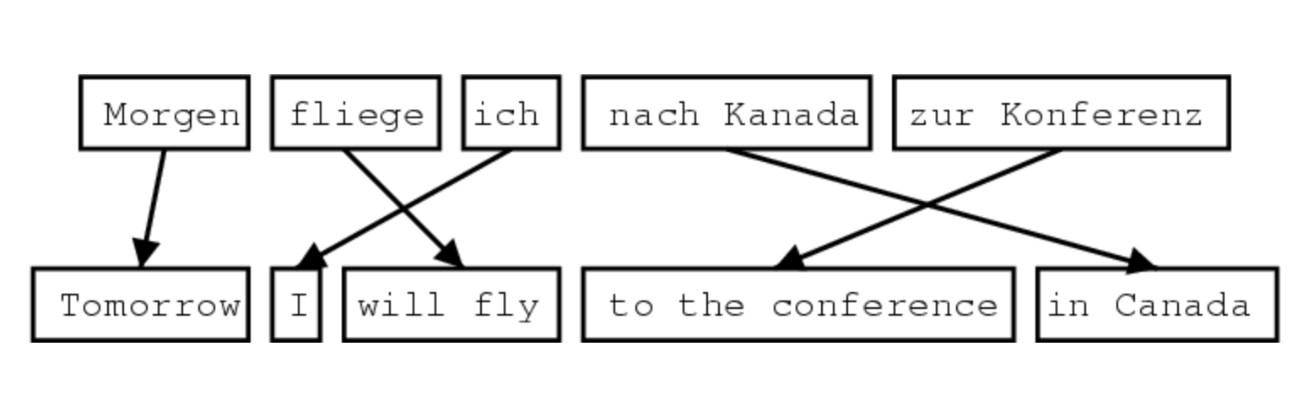
SMT에서는 다음의 두 과정을 알아야한다.
1. Alignment 학습
- 통계적 기계 번역의 핵심은 단어 또는 구 단위의 alignment(대응 관계) 를 학습하는 것.
- 정보원:
- 평행 말뭉치 (parallel corpus): 특정 단어나 구가 얼마나 자주 함께 나타나는지.
- 위치 정보: 문장에서의 단어 위치를 참고.
- Alignment는 범주적(categorical) → 확률적 개념이 아니라서 잠재 변수(latent variables) 로 다룸.
- 따라서 학습 시 EM 알고리즘(Expectation Maximization) 같은 특별한 기법 필요.
- 예전에는 이런 latent variable 기반 알고리즘을 CS224N에서 많이 다뤘지만, 지금은 잘 다루지 않음. (더 배우려면 CS228 참고)
2. Decoding 과정
-
- 번역 모델 + 언어 모델을 합쳐 가장 가능성 높은 번역을 찾아야 함.
- 모든 후보를 나열하면 지수적 비용 → 불가능.
- 따라서 문장을 부분 단위로 나누고, 독립 가정(independence assumption)을 둔 뒤, 탐색(decoding) 과정을 통해 가장 자연스러운 번역을 선택.
- 문제는 언어마다 어순이 다르다는 점이므로, 단순 생성 모델보다 복잡한 디코딩 절차가 필요.
요약하자면, Statistical Machine Translation(SMT)는 2010년까지 주류를 이끈 연구분야였다.
꽤 성공적이었지만, 언어모델과 번역 모델 외에도, 어순 재배열 모델, 활용형 처리 모델, 그리고 수많은 피처 엔지니어링이 필요로 했다.
(여러 컴포넌트를 따로 설계 해야했고, 언어 모델이 n-gram기반이라, 긴 문맥을 잘 못잡는다. 시스템 구조가 복잡하고 유지보수 어렵다).
따라서, 등장한것이 'Neural Machine Translation' (NMT)

2. new neural architecture : sequence to sequence
SMT에서 넘어온 NMT에 대해서 알아보자.
NMT는 neural network를 machine translation을 하는데 도입한 것으로, 2014년에 등장하면서 엄청난 발전이 일어났다.
이 때 사용하는 모델을 seqeunce to sequence(seq2seq)라고 하는데 말 그대로 문장에서 문장으로 번역하는 것을 의미한다.
또한, 이 때 학습할 때 end-to-end로 진행되는데, 이는 구식 기계 번역 시스템처럼 여러 개의 분리된 구성 요소로 이루어진 것이 아니라, 전체 시스템을 하나로 학습하는 방식을 의미한다.
seq2seq는 두개의 신경망을 필요로 하는데, 주로 RNN(LSTM)을 2개 사용한다.
- Encoder RNN : 입력 문장을 차례대로 읽고, 문장의 의미를 압축하여 context 벡터 (encoding)로 변환.
- Decoder RNN : 이 context 벡터를 받아, 목표 언어로 된 문장을 한 단어씩 생성.

위의 예시를 보면,
1. 왼쪽: Encoder RNN
- 입력 문장(예: 프랑스어 “il a m’ entarté”)이 단어 단위로 들어옵니다.
- Encoder RNN은 단어를 순차적으로 읽으며 문맥을 요약하고, 마지막 hidden state를 통해 문장 전체의 의미(encoding) 를 추출합니다.
- 이 encoding은 Decoder RNN의 초기 상태로 전달됩니다.
- 즉, 원문 문장의 정보를 하나의 고정된 벡터로 압축해 저장하는 단계입니다
2. 오른쪽: Decoder RNN
- Decoder RNN은 Encoder가 전달한 encoding을 바탕으로 번역을 시작합니다.
- 먼저 <START> 토큰을 입력으로 받아 첫 번째 단어(he)를 출력하고, 그 예측값을 다시 다음 입력으로 사용합니다.
- 이런 방식으로 “he → hit → me → with → a → pie” 처럼 단어를 한 개씩 생성해 나갑니다.
- 마지막에는 <END> 토큰이 나오며 문장 생성을 종료합니다.
*** Training VS Test
위의 예시 사진에서는, decoder의 각 state출력(prediction)을 다음 state의 입력으로 사용하였다.
예를 들어, <START> token 다음으로 he를 예측하였다면, 다음 hit을 예측하기 위해 he를 입력받은것처럼 말이다. 그러나, 이러한 방식은실제로 문장을 생성하거나 test할때만 그러는 거지, training(학습시)에는 teacher forcing 방식으로 정답 단어를 입력으로 준다.
이러한 Seq2Seq모델은 NLP에서 매우 강력하고 널리 사용되는 기본적인 신경망 구조가 되었다. 역사적으로 Machine Translation에서가장 먼저 큰 성공을 거둔 분야 였지만, 그 후에는
- Summarization(long text -> short text)
- Dialogue (previous utterances -> next utterance)
- Parsing (input text -> output parse as sequence)
- Code generation (natural language -> python code)
와 같이, Seq2Seq는 단순한 번역기가 아니라, 입력 시퀸스를 다른 형태의 출력 시퀸스로 변환하는 범용 프레임워크로 사용되었다.
-Conditional Language Model
seq2seq은 위와 같은 구조때문에 'Conditional Language Model'이라고 할 수 있다.
이는, seq2seq이 문장을 예측할 때, 원문 문장 x에 조건(conditioned)되어 있기 때문이다.

따라서, 이런식으로 조건부확률 식으로 표현할 수 있는데, 수식측면에서 불확실성이 적어진다. 또한, 직관적으로, 다음 예측할 단어의 후보가 줄어든다. y1,..yT-1,x가 있을때 다음 단어 yT가 나올 확률이기 때문이다.
(특히, x 즉, 원문이 강한 힌트를 줘서 다음 단어의 분포가 훨씬 뾰족해진다.-> 정확도 상승)
그렇다면, 어떻게 NMT system을 train할 수 있을까?
우선, big parallel corpus가 필요하다
ex) UN 회의록에서 영어-프랑스어 parallel data.
이렇게 병렬 문장이 준비되면, 우리는 소스 문장과 타깃 문장을 묶어 배치 단위로 학습에 사용한다.
먼저 소스 문장은 인코더 LSTM을 통해 인코딩된다. 그리고 이 인코더의 마지막 hidden state를 타깃 LSTM(디코더)의 초기 상태로 전달한다
디코더는 이제 한 단어씩 예측하면서 학습한다
즉, 첫 번째 단어를 예측하고, 예측값과 실제 첫 단어가 얼마나 다른지 비교한다(teacher forcing).
그런 뒤 두 번째 단어도 같은 방식으로 진행한다.
모델이 잘못 예측하면 그만큼 손실(loss)을 얻게 되며, 이는 “정답 단어를 생성할 확률의 음의 로그(-log P)“로 계산된다.
이렇게 문장을 따라가면서 teacher forcing 방식으로 각 단계마다 정답 단어를 입력해주고, 예측과 실제 값의 차이를 손실로 계산한다.
그 손실은 네트워크 전체로 역전파(backpropagation) 되어 모델의 파라미터가 업데이트된다.
이 방식의 핵심은 end-to-end 학습이라는 점이다.
최종 손실에서 시작해 디코더뿐만 아니라 인코더까지 모든 파라미터가 함께 학습되고 조정된다.
덕분에 인코더가 더 좋은 표현을 학습하여, 디코더가 번역할 때 더 유용한 정보를 전달하게 된다.

-Multi-layer RNNs (stacked RNNs)
지금까지 설명한 RNN은 시간축으로만 펼쳐지는 구조였지 수직방향(layer층수)는 single layer였다.
하지만, RNN을 수직으로 여러층으로 쌓는 것도 성능향상에 많은 도움을 준다.
이렇게 여러층을 쌓은 모델을 'Multi-layer RNN'이라고 한다.
RNN는 대체적으로 층수에 따라서 다음과 같이 저수준->고수준으로 바뀌는데
- lower RNN : 저수준 특징 (단어, 짧은 pattern)
- higher RNN : 고수준 특징 (구문, 의미적 맥락 ..,etc)
점점 더 복잡하고 추상적인 표현을 학습할 수 있는 것이다.

하지만 깊이가 깊을수록 성능이 좋은 것은 아니다.
2017 paper, Britz et al. find that for Neural Machine Translation에 따르면 NMT에서 encoder RNN은 2~4층, decoder RNN은 4층이 가장 성능이 좋았다고 한다.
일반적으로 encoder는 1층보다는 2층이 훨씬 좋고, 그 이후에서는 큰 영향은 없다고 한다. 물론 가지고 있는 data에 다르겠지만..
단순하게 층을 쌓는것은 큰 의미가 없고, residual connection과 같은 추가적인 연결을 도입해야 성능향상을 가능하다고 한다.
(후에 배울 Transformer와의 차이점. transformer는 12,24층.. 과 같이 깊은 층을 사용)
-Decoding 방식들
NMT에서 decoding을 하는 여러 방식들이 있는데, 기본적인 것부터 성능이 좋은 순으로 알아보자.
-Greedy Decoding
앞에서 설명한 일반적인 decoding방식으로, 문장을 생성할 때(decoding), decoder가 매 단계에서 가장 확률이 높은 단어(argmax)를 선택한다.
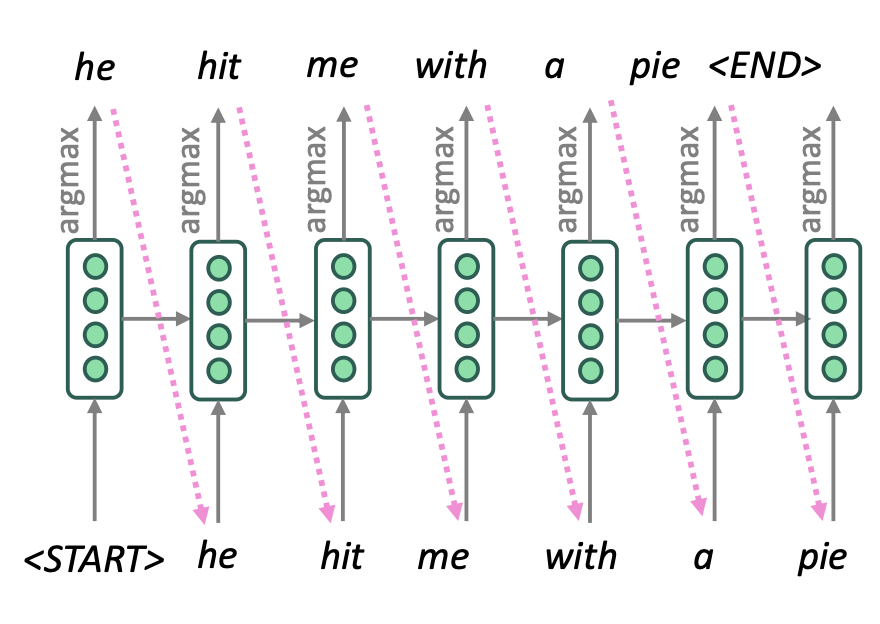
그림처럼 <START>에서 시작해,
- 첫 단어: 확률이 가장 높은 “he” 선택
- 다음 단어: “hit”
- 이어서 “me”, “with”, “a”, “pie” … <END> 까지 선택
구현이 단순하고 계산량이 적고, 빠른 문장을 생성할 수 있지만,
Problems are..
매순간 국소적으로(best locally)가장 좋은 선택을 택하기 때문에, 더 좋은 전체 문장(global optimum)을 만들 기회를 놓칠 수 도 있다. 한번 잘못하면 '그 결과에' 갇히는 문제 때문.. (결정을 취소할 수는 없기 때문)

이런식으로 'he hit me with a pie'가 되어야 하는데 'he hit a'가 만들어진 경우이다. 'a'도 충분히 등장할만한 단어지만, 문장 전체로 생각하면 알맞지 않은 예측이다.
-Exhaustive Search Decoding
완전탐색을 사용한 디코딩 기법으로, 이론적으로 모든 가능한 문장 y를 생성해서 확률을 계산해 가장 큰값을 채택한다.
즉 global optimum을 찾는 방식이다.
그러나, 문장길이가 T고, vocab집합이 V일때, 총 경우의수는 $V^T$ 가 되어버려
시간복잡도가 $O(V^T)$는 사실상 사용할 수 없는 수치이다.
따라서 'beam search'와 같은 heuristic한 방식을 사용한다.
-Beam Search Decoding
heuristic한 방식으로 탐색을 현실적으로 줄여서 좋은해를 찾는 방식이지 꼭 최적은 아니다.
다음과 같은 방식으로 decode하게 된다.
각 시점마다 상위 K개의 후보 (beam size)만 유지한다.
-> 즉, '가능한 모든 후보를 다 보진 않고, 그 중 유망해 보이는 것만 유지하자' 라는 전략!
NMT에서는 beam size를 주로 5~10정도의 작은 값을 사용한다.
decoder는 가장확률이 높은 k개의 부분번역(hypothesis = prefix of translation)을 추정하게 된다.
또한, 각 hypothesis는 지금까지 생성된 단어들의 음수 log prob(점수)를 가지며, 가장 덜 음수인 값을 최선의 후보로 선택한다.
다음의 beam size k =2인 예시를 살펴보자.
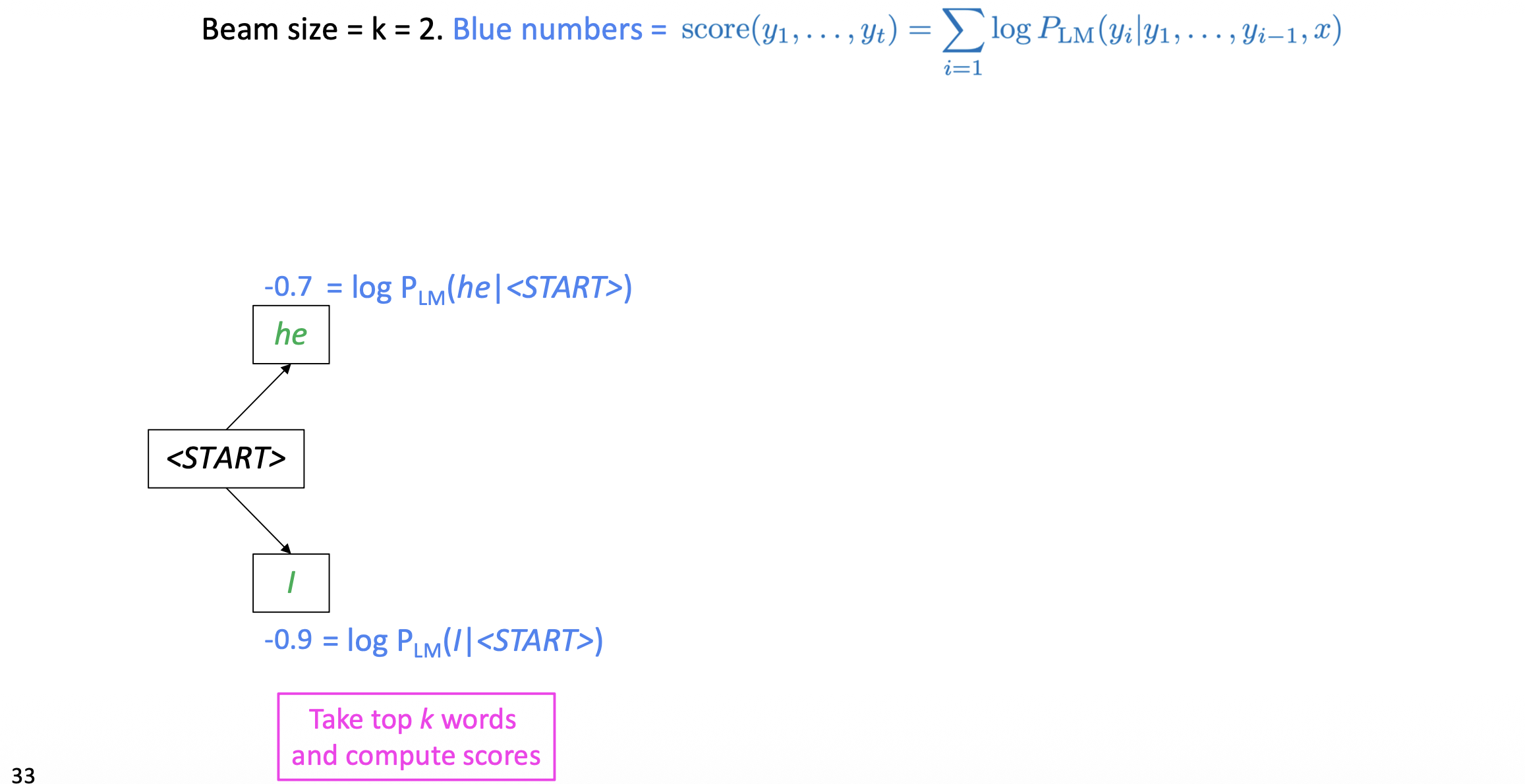
다음과 같이 처음에는 <START>토큰으로 시작하고, beam size2만큼 선택지를 체킹한다.

그 후, 각 단어별로 다음 Hypothesis들을 만들고 계산하는데, 다음 4개의 경우의 수중에서는 확률이 가장 높은 2개를 선택해서 과정을 진행한다.

위 과정을 반복해 2개의 최적의 루트를 찾을 수 있는 것이다 .

이 때, 마지막으로 종료하는 stopping criterion은 다음과 같다.
greedy decoding은 <END>token이 나오면 끝이지만, beam search는 여러 hypothesis가 존재해서, <END>가 나오는 시점이 다를 수 있기 때문에 다음의 2가지 상황에서 종료된다.
1. We reach timestep T(where T is some pre-defined cutofff)
2. We have at least n completed hypothesis
즉, 정해둔 최대 문장길이T까지 탐색하면 강제로 종료를 하든가, n개의 hypothesis가 완성되면 종료하게 된다.
그 후, 완성된 후보들 중에서 점수가 가장 높은 것을 최종 번역으로 선택한다.
주의할점은 점수계산에서 점수를 그대로 사용하지 않는다는 점이다.
systematic problem : 더 긴문장 후보들이 점수가 낮아지는 경향(확률을 곱하기 때문에, 작아지는 것은 필연)
따라서, 길이에 따라 선택의 결과가 치우쳐지면 안되기 때문에, 'normalize by length'를 해준다.

-Advantages of NMT
- 더 좋은 성능(fluent, better use of context)
- No subcomponents to be individually optimized -> end to end.
- Requires much less human engineering effort
- No feature engineering
- Same method for all language pairs
-Disadvantages of NMT
(compared to SMT)
- less interpretable(hard to debug) : 내부과정을 보기 어렵다
- difficult to control : 원하는 style을 추가하기 어렵다. ex)좀더 casual하게 해석해줘.
- safety concern : 어떤 문장을 생성할지 알 수 없다.
-How do we evaluate Machine Translation
두 개의 언어를 모두 구사하는 사람이 직접 평가하는 간단하고 정확한 방식이 있지만, 시간과 인력이 너무 많이 든다.
따라서, 자동화된 평가 방법으로 대표적으로 'BLEU'(Bilingual Evaluation Understudy)라는 것이 있다.
BLEU는 기계 번역이 생성한 문장을 **사람이 쓴 정답 번역(참조 번역)**과 비교해서 얼마나 유사한지 점수화하는 방법으로,
- 기계 번역 결과와 참조 번역 간의 n-gram precision(보통 1, 2, 3, 4-gram)을 계산.
- 예: “he hit me” 와 “he struck me” → 1-gram은 겹치지만 2-gram은 다름.
- 너무 짧은 번역이 나오면 높은 precision을 갖게 되는 문제를 방지하기 위해 **brevity penalty(길이 패널티)**를 추가.
🔹 BLEU의 장단점
- 장점 (useful)
- 빠르고 자동화된 점수 산출 가능.
- 연구와 산업에서 널리 사용되는 사실상 표준 평가 지표.
- 단점 (imperfect)
- 문장 번역은 정답이 하나가 아님 → 여러 가지 올바른 번역이 존재할 수 있음.
- 따라서 번역이 실제로는 좋은 품질인데도, 참조 번역과 n-gram이 겹치지 않으면 낮은 점수를 받음.
- 예:
- 참조: “He hit me with a pie.”
- 기계 번역: “He threw a pie at me.” → 의미상 맞지만 n-gram 겹침 적어 BLEU 점수 낮음.
-Neural Machine Translation 발전

확실히 Neural based인 NMT가 성능이 좋은 것을 알 수 있다.
NMT는 딥러닝이 NLP에 적용된 최초의 '실질적 성공 사례'로 2014년에 처음 등장하였다.
2016년 구글이 SMT->NMT로 전환하여 이후 업계에서 NMT가 표준화 기준이 되었다.
수백명이 만든 복잡한 시스템을 소규모 팀이 몇달만에 구현할 수 있게 하는 기념비적 전환점이었다.
그러나 NMT가 완벽한 것은 아니다.
많은 현실적인 문제점이 남아있다.

Out-of-vocabulary (OOV) words
- 훈련 데이터에 등장하지 않은 단어를 모델이 보면 번역이 어려움.
- 예: 신조어, 고유명사, 기술 용어 등.
Domain mismatch
- 훈련 데이터와 실제 사용하는 데이터의 도메인이 다르면 성능이 급격히 떨어짐.
- 예: 뉴스 데이터로 학습했는데, 의료 논문 번역에 쓰면 정확도가 낮아짐.
Maintaining context over long text
- 긴 문서나 문맥이 긴 대화에서는 앞뒤 맥락을 유지하기 어려움.
- 한 문장 단위로는 괜찮아도, 여러 문장이 이어진 글에서는 번역 일관성이 무너짐.
Low-resource language pairs
- 영어 ↔ 프랑스어처럼 데이터가 많은 언어쌍은 잘 되지만,
- 소수 언어나 저자원 언어(예: 스와힐리어 ↔ 한국어)는 데이터 부족으로 품질이 낮음.
Sentence meaning capture 실패
- 단어 단위는 맞아도 전체 문장 의미를 놓치는 경우.
- 직역은 되지만 의미는 어색한 번역.
Pronoun resolution 문제
- 대명사(he, she, it, they 등) 또는 zero pronoun(주어 생략 현상, 특히 한국어나 일본어) 번역에서 오류.
- 예: “그”가 사람인지 물건인지 구별 못하는 경우.
Morphological agreement errors
- 언어마다 성(gender), 수(number), 시제(tense) 등이 일치해야 하는데 잘못 처리하는 경우.
- 예: 영어 → 프랑스어 번역 시, 명사 성별에 따른 형용사 변화 등을 잘못 적용.
3. new neural technique : Attention (~Lec8)
seq2seq이후에 등장한 것이 attention이라는 기법이다.
seq2seq에는 구조적인 bottleneck problem이 존재한다.
이는 마지막 Hidden state를 encoder에서 만들고 decoder에 전달하게 되는데, 이 Hidden state는 문장의 모든 정보를 가지고 있어서 bottle neck이 발생할 수 있다.
대신, 마지막 hidden이 아니라 전체의 평균을 사용하는 방식도 가능하지만, 이는 setiment task에서나 잘 작동하지 순서가 중요한 MT에서는 썩 좋지는 않다.
따라서, 인간이 문장을 번역하는 방식, 즉, 중간중간 원문을 계속 참고하는 방식으로 나온 idea가 바로 'attention'이다!!
주요 내용은 다음강의인 Lecture 8에서 다루지만, 간단한 기본 idea만 알고 넘어가자.
핵심 idea는 다음과 같다.
decoder가 매 단계마다 출력을 생성할 때, 인코더 전체 출력을 직접 참고한다. (입력 문장에 대한 모든 Hidden state)
구체적으로, decoder의 Hidden state와 encoder의 각 Hidden state를 비교해 'Attention Score'(유사도)를 계산하고 softmax를 통해 확률분포를 얻는다. 이 확률분포는 현재 번역할 단어와 가장 관련이 깊은 입력 단어는 어디인가? 를 알려주게 된다.
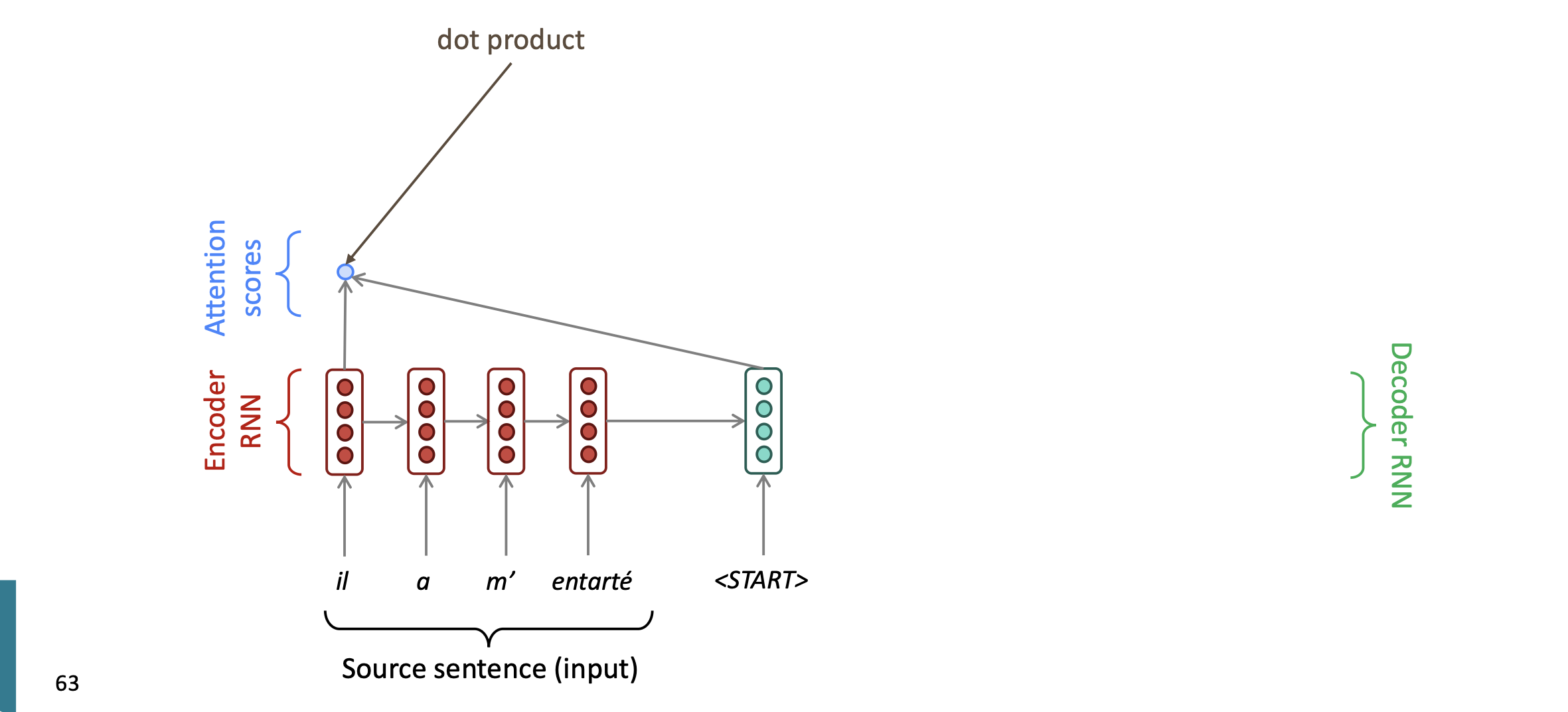
이 확률 분포를 가중치로 사용해 encoder hidden state들의 가중합을 계산하는데, 이 결과 vector가 'attention output'이다.

이 attention output 과 decoder의 Hidden state와 결합하여 softmax를 거치면, 현재시점에서 번역할 단어를 예측할 수 있다.
(일부모델은 이전 step의 attention output을 다음 step의 입력에도 함께 넣어주는 방식을 사용한다.)

추가적인 내용과, 수학적인 접근은 다음 강의를 참고하자.
'LLM' 카테고리의 다른 글
| Stanford CS224N Lec10 (Winter 2021) (1) | 2025.10.09 |
|---|---|
| Stanford CS224N Lec9 (Winter 2021) (0) | 2025.10.06 |
| Stanford CS224N Lec6 (Winter 2021) (0) | 2025.09.22 |
| Stanford CS224N Lec5 (Winter 2021) (0) | 2025.09.15 |
| Stanford CS224N Lec4 (Winter 2021) (0) | 2025.09.03 |