Lecture 3: Backprop and Neural Networks
강의 목차
- Matrix Calculus
- Backpropagation
1. Matrix Calculus
기본적인 미분에 관한 수학내용들이다.
기초부터 다시 보자.
-Single Variable (scalar to scalar)
변수가 한개인 미분은 우리가 흔히 사용하는 미분이다.
-Multi Varaible
1) multi inputs & single output (vector to scalar)
f(x)가 f(x1,x2,...xn)과 같이 n개의 변수로 이루어져 있을 때 (n inputs and 1 output)
f(x)의 미분은 gradient라고 하고, partial derivatives(편미분)을 모아둔 vector이다.
$ \frac{\partial f}{\partial x} = [\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2}.., \frac{\partial f}{\partial x_n}]$
2) multi inputs and multi outputs (vector to vector)
f(x)가 입/출력이 모두 vector인 경우, f(x)의 미분 결과는 Jacobian Matrix이다.

-Chain Rule
다변수 미분을 할 때 사용한다.


-nueral network derivative
이제 neural network의 식을 미분해보자.

위의 식은 neural net의 최종식인 s를 bias 'b'로 미분해 보았다.

이건, s를 가중치 행렬 'W'로 미분한 것인데, 위의 'b'로미분했을 때와 유사한 구조를 가진다.
chain rule로 인해 ds/dh * dh/dz의구조는 동일하고, 마지막 dZ/db와 dZ/dW만 다르다. (Z = Wx + b)
따라서, 이렇게 반복적으로 나오는 구조를 'local error signal'로 정의하고, 반복 계산을 줄여줄 수 있다.
저기서 uT와 f'(z)사이의 원형 기호는 'hardmard product'(element-wise product)로 행렬의 같은 위치의 원소끼리 단순 곱을 해주는 것이다. 수학의 matrix multiplication과는 다르다.

이제, ds/dW에서 local error signal부분을 제외한, dZ/dW를 구해야 한다.
Z는 Wx+b로 W로 미분을 하면 W가 되고, local signal과의 곱이 될 것이다.
$그러나, 답은 \delta^{T}x^{T} 이 된다. $
그 이유를 살펴보자.
우리가 구할려는, ds/dW에서 s는 scalar value이고, W는 n by m matrix이다.
따라서, scalar을 행렬로 미분하면, jacobian 형태로 길이가 nm인 row vector가 만들어진다.
하지만, update rule을 살펴보면
$W\leftarrow W- \alpha \frac{ds}{dW}$
인데, n by m 인 W에서 1 by nm을 subtract하는 것은 불가능하다.
따라서, delta와 x 모두 transpose한 것을 사용한다.
이러면 delta transpose는 n by 1이고 x transpose는 1 by m 이라, 둘의 곱은 n by m 이 되어서 subtracting이 가능해진다.
이렇게 차원을 변형해서 계산을 해주는 것은 nerual network 쪽 수학에서 많이 사용하는 방법이고, 수학적으로 동치이다.
** 참고.. 각 변수의 shape.
$W\in R^{n*m}$
$Z\in R^{m*1}$
$X\in R^{m*1}$
$\delta\in R^{1*n}$
2. Back Propagation

위의 사진에서 검정색 줄로, x부터 순차적으로 nerual network의 식들을 계산하는 것을 forward propagation(순전파)라고 하고,
파란색 줄로, 결과 값에서 거꾸로, 식들을 미분해서 다시 돌아가는 과정으로, Loss에서 거꾸로 가며 각 gradient를 전달한다. 이 gradient를 이용해서, 가중치들을 update해주게 된다.
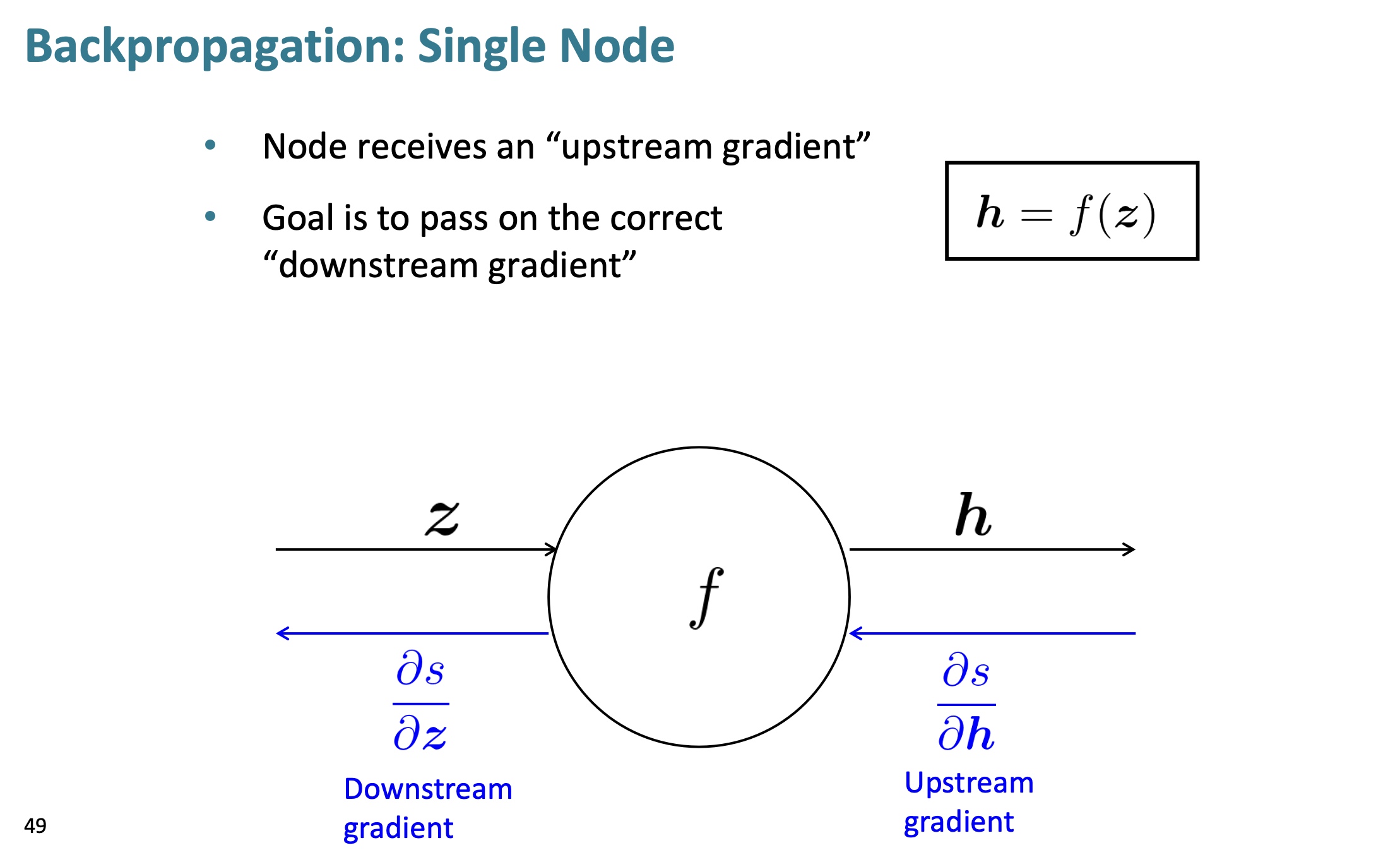
이해하기 쉽게, 하나의 노드에서 역전파 과정을 살펴보자.
우선, 용어를 정의한다.
downstream gradient : 노드의 왼쪽
upstream gradeint : 노드의 오른쪽.
backpropagation의 main purpose는 upstream gradient를 이용해서, downstream에 알맞은 gradient를 계산해주는 것이다.
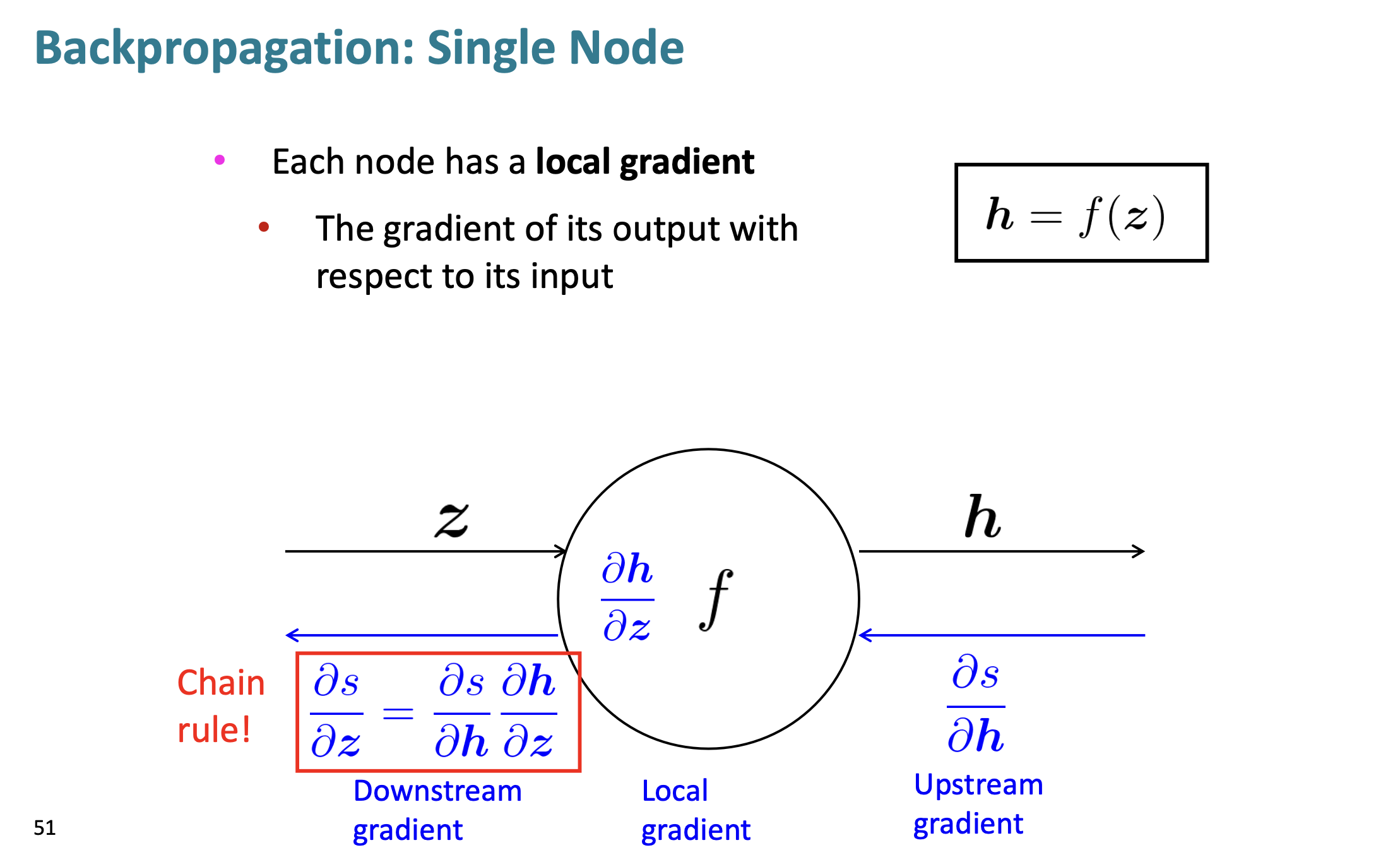
chain rule을 사용하면 downstream gradient = local gradient x upstream gradient 인 것을 알 수 있다.

이런식으로 변수가 여러개라면, 각각 변수에 대한 downstream gradient를 구한 후, 추후에 더해주게 된다.
더 자세한 것은 아래 실제 예시를 통해 확인하자.

우리가 실제로 backpropagation의 상세 계산을 할일은 없으니, 참고만 하자.
위의 예시에서도 알 수 있듯이, gradient를 downstream으로 전달하는 과정에서, 중복으로 사용되는 값들이 많다. 따라서, 이들은 반복적으로 사용해주기 위해 따로 누적해서 저장해준다.

Fprop : topological sort순으로 방문해서(의존성 없는 노드), 최종층 까지 계산.
Bprop : 출력 ds/ds을 1로 초기화 해주고, reverse topological sort의 역순으로 진행한다.
따라서, F,B모두 O(# of edge)로 동일하다.
'LLM' 카테고리의 다른 글
| Stanford CS224N Lec5 (Winter 2021) (0) | 2025.09.15 |
|---|---|
| Stanford CS224N Lec4 (Winter 2021) (0) | 2025.09.03 |
| GPT From Scratch Project (7) | 2025.08.13 |
| Stanford CS224N Lec2 (Winter 2021) (0) | 2025.06.19 |
| Stanford CS224N Lec1 (Winter 2021) (0) | 2025.06.19 |


