Lecture 1 - Intro and Word Vectors
강의 목차
- Human language and word meaning
- Word2vec introduction
- Word2vec objective function gradients
- Optimization basics
- Looking at word vectors
1. Human Language and Word Meaning
사람의 언어는 static. 의미가 고정되어있지 않다.
그 사람의 배경지식 등에 따라서 의미가 변화할 수 있다.
이를 컴퓨터로 표현하는 방식을 'denotational semantics'이라 하는데,
Denotational semantics는 프로그래밍 언어의 의미를 수학적으로 정의하는 방법이다. 쉽게 말하면, 프로그램(혹은 프로그램의 각 구문)을 수학적인 “함수”나 “수식”으로 대응시켜서, 그 구문이 실제로 무엇을 의미하는지를 형식적으로 표현하는 방식이다.
가장 처음 등장한 것은 프린스턴에서 만든 영어 어휘 데이터베이스인 'WordNet'이다.
WordNet은 단어들을 의미 단위(Synset : Synonym Set)으로 묶고, 그 사이의 관계를 그래프 구조로 저장한다.

하지만, 이러한 유의어 끼리 묶은 대규모 집합에는 사람이 사용하는 언어의 특징인 'nuance'가 담겨 있지 않다.
예를 들어, 'proficient'는 'good'의 synonym으로 묶여 있다. 그러나, good가 사용되는 문장에서 proficient로 치환할 경우 이상한 문장이 많이 만ㄷ르어진다. 또한, 새로운 단어의 업데이트가 거의 불가능하다.
따라서, 사람들이 다시 생각해서 만든것이, 'one-hot vector' (word vector) 이다 .
이는, 모든 단어를 0,1로 이루어진 벡터로 표현한 것으로,\
motel = [0 0 0 0 0 0 0 1 0 0 0 0]
hotel = [0 0 0 0 0 1 0 0 0 0 0 0]
와 같이 표현하지만, 단어의 의미는 전혀 내포하지 못한다. 두 단어는 비슷하지만, 두 one-hot vectors들은 orthogonal, 아무런 의미정보가 없다. 심지어, vector size(dimension)은 전체 vocab size와 동일해져, 엄청난 크기의 벡터들이 만들어져 사용이 불편하다.
2. Word2Vec Introduction/ 3. Word2Vec obejctive function gradients
위의 문제점을 개선해서 만든 것이 'Word2Vec'이다.
word2vec을 알기전에 distributional semantics(분포 의미론)에 대해서 알아보자.
👉 “단어의 의미는 그 단어가 사용되는 문맥(Context) 속에서 정의된다”라는 아이디어를 기반으로, 단어를 **통계적 분포(statistical distribution)**로 표현하는 의미론이다.
이는 언어학자 Firth의 유명한 말에서 출발했다:
“You shall know a word by the company it keeps.”
즉, word2vec은 이러한 의미론을 참고하여, 단어의 문맥(context)를 참고하여 만들어진다.
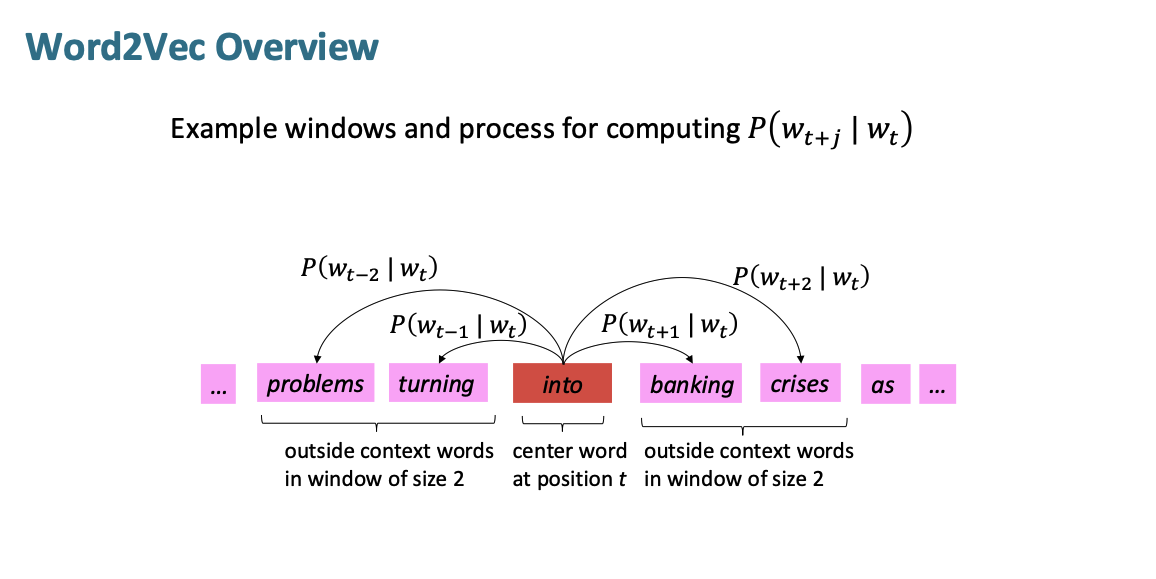
문장에서 어떤 위치 t의 중심단어가 주어졌을 때, 그 window(크기는 지정해줘야됨)의 문맥 단어들을 예측한다.
window크기가 2라면, 중심 단어 옆으로 2개 단어씩 예측한다.

L fucntion은 모든 context word가 주어진 center word로부터 잘 예측될 확률을 최대화 하는 것.
objective funtion에서는 이를 Minimize(더 쉬워서)하기 위해서, 음수를 취하고 곱의 연산을 합의 연산으로 바꾸기 위해 log도 취해준다.
그 후, corpus 크기인 T로 나누어서 평균을 취한다.

이제 중요한 것은, center word w^t 가 주어졌을 때, context word w^t+j 가 나올 확률
$P(w_{t+j} \mid w_t; \theta)$는 어떻게 계산할까?
-> softmax function을 이용해서 확률분포를 구할 수 있다.
Softmax는 벡터의 원소들을 확률 분포처럼 변환해 주는 함수이다.
$\text{softmax}(z_i) = \frac{\exp(z_i)}{\sum_{j=1}^n \exp(z_j)}$
- 각 z_i를 e^{z_i}로 변환 → 양수로 바꿈
- 전체 합으로 나눔 → 합이 1이 되도록 정규화
'LLM' 카테고리의 다른 글
| Stanford CS224N Lec5 (Winter 2021) (0) | 2025.09.15 |
|---|---|
| Stanford CS224N Lec4 (Winter 2021) (0) | 2025.09.03 |
| Stanford CS224N Lec3 (Winter 2021) (0) | 2025.09.03 |
| GPT From Scratch Project (7) | 2025.08.13 |
| Stanford CS224N Lec2 (Winter 2021) (0) | 2025.06.19 |



