Lecture 3는 'Locally Weighted Regression and Logistic Regression'에 대해서 설명한다.
강의 목차
- Linear Regression(recap)
- Locally Weighted Regression
- Probability Interpretation
- Logistic Regression
- Newton's Method
1. Linear Regression (recap)
linear regression에 대한 복습은 lecture2 글을 참고하자.
2024.04.24 - [Machine Learning] - [ML] Stanford cs229 ML Course Lecture 2
[ML] Stanford cs229 ML Course Lecture 2
Lecture 2는 'Linear Regression and Gradient Descent'에 대해서 설명한다. 강의 목차Linear Regression(Batch) Gradient DescentStochastic Gradient DescentNormal Equation 1. Linear Regression(선형 회귀)lec1에서 간단히 소개했던 regress
wm07070.tistory.com
2. Locally Weighted Regression
LWR을 알아보기 전에, 'Parametic Learning Algorithm'과 'Non - Parametic Learning Algorithm'에 대해 비교해 보자.
- Parametic Learning Algorithm
Fit fixed set of parameters(θ) to data. 즉, 고정된 θ값을 이용해서 예측을 하는 방식이다.
한번 주어진 training data set로 h(x)를 정하면 training data를 지워도 h(x)를 이용하여 예측을 할 수 있다. ex) Linear Regression, Logistic Regression
- Non Parametic Learning Algorithm
Amount of data/parameters you need to keep grows (linearly) with size of data. 즉, θ값을 주어진 데이터로 점점 키워나가는 방식으로 θ가 더 이상 고정값이 아니게 된다.
이 경우는, 초기에 주어지는 training data set을 계속 필요로 한다. 따라서, 많은 양의 데이터를 다루기는 힘들다는 단점이 있다.
ex) Locally Weighted Regression, SVM, KNN
LWR을 이해하면 두 방식의 차이를 완벽하게 이해할 수 있을 것이다.
다음과 같이, 집값들에 대한 data가 있다.
첫 번째는 feature가 2개인 간단한 일차식이고 오른쪽으로 갈수록 점점 feature가 추가된 고차식이 된다. 주어진 data만 본다면 고차식일수록 좋은 예측처럼 보이지만, 실제 세계에서는 저런 복잡한 식을 따라서 가격이 형성될 가능성은 높지 않다. (계산도 복잡해져서 좋지 않다.)
따라서, 다음과 같은 data set이 있을 때는, Locally Weighted Regression방식을 사용하자.
LWR은 이름에서 알 수 있듯이, 예측하고 싶은 x값의 locally neighborhood에 가중치를 두는 방식이다.
x의 주위 지역값들만 사용하여 일차식을 만들어서 예측한다.
다음과 같이 w를 추가한 식을 이용한다.

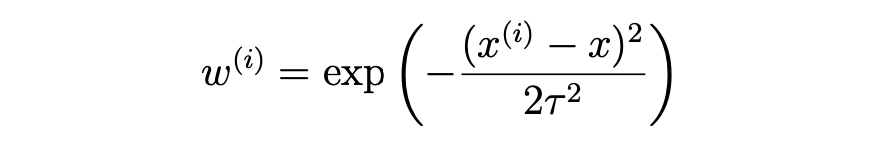
위의 식은 가중치로, 자세히 살펴보면,
$x^{i} - x$ 는 비교대상인 local neighborhood와 x값과의 거리 차이이다. If $\left|x^{i} - x \right|$ 가 작아지면, $w^{(i)} \approx 1$ 이고, If $\left|x^{i} - x \right|$ 가 커지면, $w^{(i)} \approx 0$ 이다. 즉, 우리의 x값과 거리과 작은 값들은 가중치가 커지고, x값과 거리가 멀어지면 가중치가 작아진다는 것을 알 수 있다.
가중치 함수의 분모에 위치하는 변수 τ(tau)는 'bandwith'라고 하며 반영크기를 정해준다.
또한, 가중치 함수의 형태는 가우시안 분포와 유사하지만, 가우시안 분포와는 아무런 상관은 없다.
이러한 특징을 종합하면, LWR은 low dimensional but large data set일 때 사용하기 좋다.
3. Probability Interpretation
머신러닝에 대한 확률적 해석을 통해, linear regression에서 왜 우리가 cost function으로 least square(제곱식)을 쓰는 이유를 알 수 있다.
target value가 다음과 같은 식으로 표현할 수 있다고 가정하고 시작하자.

앱실론은 가우시안 분포를 따르는 distributed IID라 가정하는데, IID는 independently identically distributed로 독립이다. 실제세계에서는 IID는 불가능한 소리이지만, model에서는 꽤 좋은 조건으로 가정해 보자.
$$\epsilon ^{(i)} \sim N(0,\sigma ^{2})$$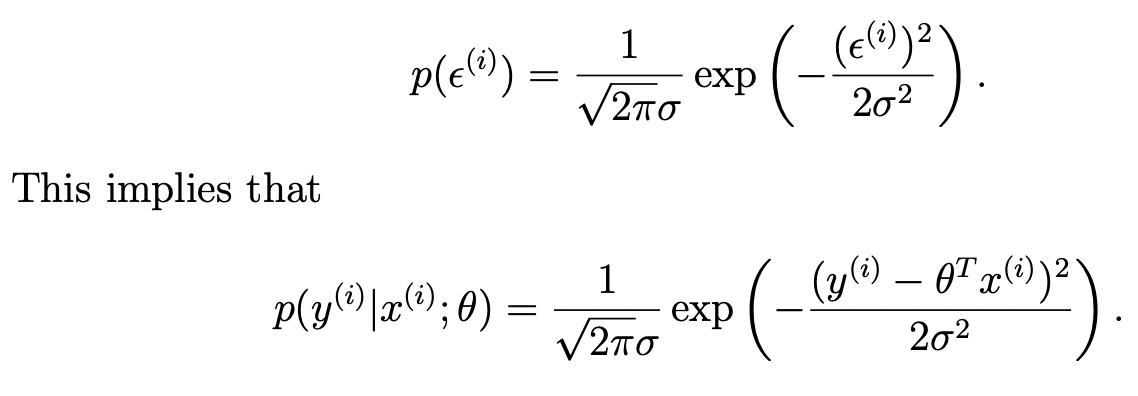
cf) 표기법에 대한 정리
교수님께서 간단하게 표기법에 대한 정리를 해주셨다. 위의 식을 읽을 때는, probability distribution of y given x and parametrized by θ라 하는데, ';'(semicolon)을 꼭 사용해야 한다. 만약 ', '(comma)를 사용하면 θ변수에 대한 conditioning이 되어버리는 것으로, θ는 random var이 아니어서 해당되지 않는다. θ는 그저 parameter일 뿐이다.
위의 개별 데이터에 대한 확률 분포를 고려하여, 전체 데이터에 대한 확률 분포를 likelihood function으로 표현해 보자.
X는 design matrix로 모든 x에 대한 정보를 가지고 있고, y 벡터도 모든 label값을 가진다.
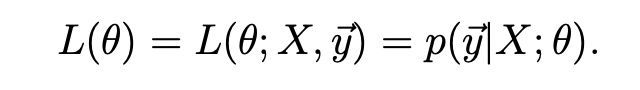

이제, L(θ)의 maximum을 구하는 'maximum likelihood estimation' (MLE)를 구해보자.
cf) MLE를 구하기 전에 likelihood와 MLE에 대해 자세히 알아보자.
likelihood를 번역하면 '가능도' 혹은 '가능성'으로 확률을 뜻하는 probability와 해석의 큰 차이가 없다.
그러나, 통계학에서의 정확한 의미를 살펴보면, probability는 확률분포가 고정된 상태에서, 관측값 혹은 관측구간의 그 분포 안에서 존재하는 확률을 구하는 것이고, likelihood는 관측값이 고정된 상태에서, 그 값이 어느 확률분포에서 나오는지에 대한 확률을 구하는 것이다.
이러한 이유에서, 위의 p(y|x;θ)식에서 자연스럽게 L(θ)로 넘어온 것이다.(고정된 θ, 일 때 y와 X에 대한 분포).
MLE는 이러한 likelihood를 이용해서 최적의 θ값을 추정하는 방법인데, likelihood가 확률분포의 확률이므로, 이 값이 최대일 때, 최적의 θ일 것이라는 추정은 자연스럽다.
계산의 편의를 위해 대부분 L(θ)에 로그를 씌운 log likelihood를 사용한다
(로그를 씌워도 계산에 영향을 주지는 않는다.)
(교수님도 용어의 통일성을 위해서 'likelihood of the parameter' 그리고 'probability of the data'라고 부를 거라고 하심. 즉, 다시 한번 likelihood는 parameter θ가 변할 때 사용, probability는 θ가 고정이고 data가 변하면 사용하는 것이다.)
앞으로 log L(θ)를 l(θ)로 정의하고 계산을 진행해 보자.

여기서 θ와 관련 없는 항을 제거하면, -가 붙은 두 번째 항만 남게 되는데 l(θ)의 max값을 구하는 것이므로, 다음과 같이 음의 항을 제거한 두 번째 항의 min 값을 구하면 된다.

이는 우리가 앞에서 사용했던 cost function인 J(θ)와 동일한 것을 알 수 있고, 이러한 이유 때문에 우리가 least-square regression이 natural algorithm method라 할 수 있는 것이다.
(그러나, 이러한 확률적 접근이 least-squares가 완벽한 방법이라는 것을 증명해주지는 않는다. 더 좋은 방법이 있을 수도 있다.)
4. Logistic Regression
이번에는 supervised learning의 다른 종류인 'Classification Problem'에 대해 알아보자. 앞에서 계속 다루었던 housing price는 y(가격)가 continuous 한 regression problem이었지만, 종양의 음/양 여부 혹은 이메일의 스팸 여부와 같이 y값이 discrete value일 경우, 이를 classification problem이라 정의하게 된다.
이번에는 y가 0 or 1만 가능한 binary classification problem에 대해서만 집중해 보자.
우선, 앞에서 배웠던 linear regression algorithm을 classification problem에 도입해보자.
직관적으로 봤을때도, y는 0과 1 두 가지 값만 나와야 하는데, linear regression의 h(x)는 그렇지 않다는 점에서 이상하다고 생각할 것이다.
또한, 이상치에 대에서 예측 model이 너무 쉽게 바뀐다는 단점도 있어 매우 좋지 않은 model이 될 것이다.
이를 해결 하기 위해 우리는 새로운 hypothesis h(x)를 다음과 같이 정의해 보자.
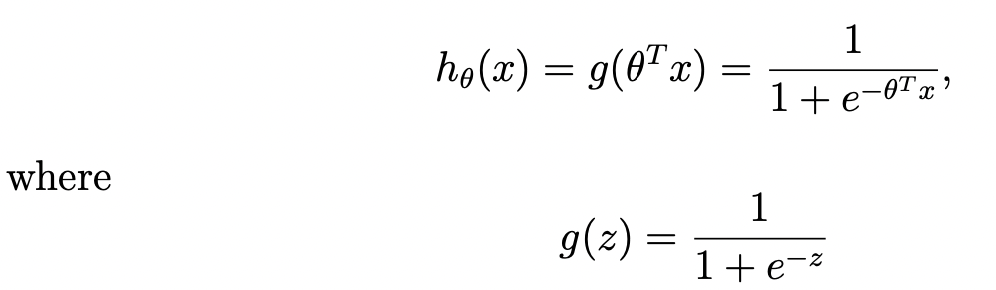

이제 y=1 또는 y=0일 확률을 다음과 같은 식으로 표현할 수 있다.

이를 한 줄의 식으로 줄여서 다음과 같이도 표현할 수 있다.

이제 3번 항목의 '확률적 접근'에서 했던 likelihood 함수를 이용해서 최적의 θ을 구하자.
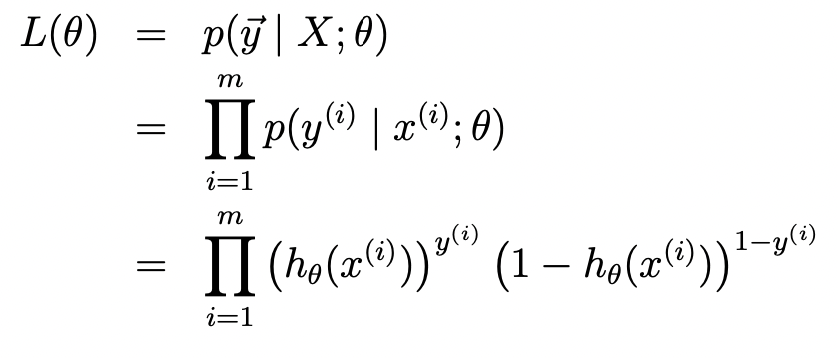
계산의 편의를 위해 다시 로그를 취하고 likelihood maximize 기법을 사용해 보자.
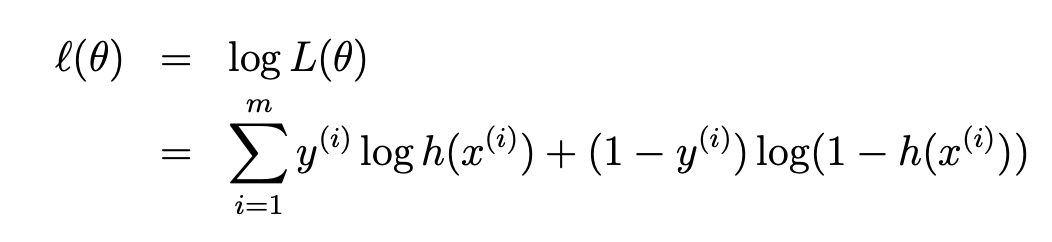
log likelihood를 최대화하기 위하여, lecture2에서 배웠던 gradient descent와 유사한 gradient ascent 방법을 사용할 수 있다.
cost function을 최소화하기 위해서 사용했던 descent와 달리
ascent에서는 likelihood함수를 최대화하기 위한 방식이라 부호가 +이라는 점에 주목하자!

미분과정은 강의 자료에 있으므로 생략..
최종결과는 다음과 같다.

위의 식은 lms method에서 gradient descent의 결과와 유사한 형태를 보인다. 그러나 같은 알고리즘도 아니고, 위의 식은 non linear function(비선형 함수, 곡선 형태)로부터 나온 것이다.
다른 알고리즘이지만 비슷한 형태의 update rule이 나온 이유는 추후의 'generalized linear model' (GLM)에서 배울 예정!!
5. Newton's Method
마지막으로, l(θ)를 최대화하기 위한 다른 방법인 'newton's method'를 알아보자.
위의 gradient ascent 방식은 꾸준히 update를 해주어야 하므로 많은 iterations들이 필요로 하지만, newton's method는 비교적 적은 횟수의 iteration으로도 최적의 값을 구할 수 있다. 그러나, 한번 한 번의 계산이 복잡해서 장단점이 존재해 알맞은 방식을 선택하자.
newton's method는 f라는 함수가 있을 때, f(θ) = 0을 만족하는 θ를 구하는 것이 목표이다.
우리는 max l(θ)하는 것이 목표이므로, newton's method를 이용해서 l'(θ) = 0을 만족하는 θ를 찾는 것이 목표.
아래와 같은 과정을 반복한다.

임의의 $\theta^{(0)}$ 를 선택한다. $f(\theta^{(0)})$ 에서의 접선을 만들고 접선의 x절편을 $\theta^{(1)}$ 으로 정의한다.
$\theta^{(0)}$ 와 $\theta ^{(1)}$ 사이의 거리를 $\Delta$로 정의한다.
$\theta ^{(1)} =\theta^{(0)} -\Delta$
접선의 기울기는 다음과 같으므로, $\acute{f}(\theta ^ {(0)}) = \frac{f(\theta ^{(0)})}{\Delta}$
즉 $\Delta = \frac{f(\theta ^{(0)})}{\acute{f}(\theta ^ {(0)})}$
$$\theta^{(t+1)}:= \theta ^{(t)} - \frac{f(\theta^{(t)})}{\acute{f}(\theta ^ {(t)})}$$
한단계를 진행할 때마다 θ의 개수가 점점 늘어나는데, 적은 횟수로도 f(θ) = 0을 만족하는 θ를 매우 근사하게 추정할 수 있다. 이는 newton's method가 quadratic convergence를 따르는 점에서 알 수 있는데, 이 때문에 실제값과 차이(오류)가 제곱에 비례해서 줄어들게 되어 적은 횟수의 연산으로 최적의 값을 구할 수 있다.
ex) 0.01 error -> 0.001 error -> 0.0000001 error
따라서, 이러한 newton's method을 이용해서 l'(θ)=0인 θ를 다음과 같이 구할 수 있다.
f(θ) 대신 l'(θ)를 대입하자.
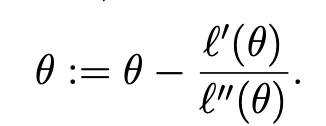
만약, θ가 vector(고차원)일 경우에는 다음과 같은 결과가 나온다.

이렇게 고차원일 경우, 행렬의 계산을 하게 된다. 행렬의 계산은 시간이 오래 걸리거나 계산이 불가능할 수 있어서, 여기서 초반에 언급한 newton's method의 단점이 드러나게 된다.
'Machine Learning' 카테고리의 다른 글
| [ML] Stanford cs229 ML Course Lecture 2 (0) | 2024.04.24 |
|---|---|
| [ML] Stanford cs229 ML Course Lecture 1 (0) | 2024.04.23 |

