Lecture 2는 'Linear Regression and Gradient Descent'에 대해서 설명한다.
강의 목차
- Linear Regression
- (Batch) Gradient Descent
- Stochastic Gradient Descent
- Normal Equation
1. Linear Regression(선형 회귀)
lec1에서 간단히 소개했던 regression problem을 해결할 방법을 알아보자.

위의 사진에서 hypothesis인 h(x)를 구하는 것이 선형회귀의 주목적이다.
lec 1에서 소개했던 house price problem을 상기시켜 보자. data set에는 집크기와 그에 알맞은 label인 집가격이 존재했다. 이번에는 feature을 1개 추가해서, 집크기와 방개수, 총 2개의 feature (2-dimension)이 존재한다.

cf) 앞으로 많은 수학식이 나올 텐데, 헷갈리지 않으려면 미리 변수 정리를 하고 들어가자.
θ : "parameter (weight)"
X : inputs(features)
Y : outputs(labels)
(x, y) : "training set"
(x(i), y(i))
m : "# of training example" (# of rows in table)
n = "# of feature"
linear regression에서는 h(x)를 다음과 같이 정의한다.

여기서 세타와 x벡터는 n+1 크기의 차원을 가진다. (feature + 1)
h(x)식을 파악했다면, 실제 y값과 가장 근접한 h(x)를 만들어주는 세타를 설정해야 된다. 이는 주어진 training data를 이용한다.
이때, 'cost function'이라는 값을 사용한다.
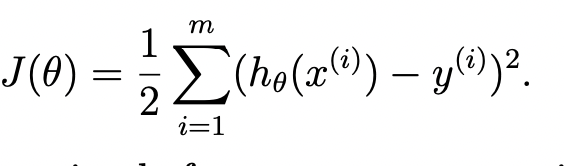
h(x)와 y값의 차이를 제곱하는 이유는 뒷 lecture에서 나올 예정이라고 함. 제곱, 절댓값, 루트 등 양수를 유지하기 위한 다양한 방법이 있긴 하다. 1/2은 제곱을 미분했을 때, 계산의 편의를 위해서 임의로 실수배를 해준 것이다.
이제 2번 목차인 gradient descent에서 cost function을 최소화하는 방법을 알아보자.
2. Gradient Descent(경사 하강법)
J(θ)의 최솟값을 찾는 알고리즘 중 하나이다. (다양한 방법이 있다.)
한 번에 θ 값을 구하는 것이 아니라, 반복적으로 θ를 변화시키면서 최적의 값을 구해야 한다.
알고리즘 단계
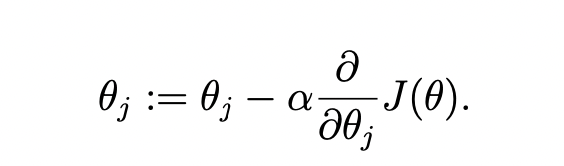
1. 우선 some θ로 시작을 한다. (θ = 0 벡터)
2. 위의 식에 알맞은 θ값을 계속 업데이트해 준다. (j = 0,..., n)
cf) 여기서 α는 learning rate로, 0보다 큰 값을 가진다. 이번 lec에서는 교수님께서 깊게는 설명하지 않으셨지만 보통은 0.01의 값으로 시작한다고 한다. α의 크기가 너무 큰 경우에는 θ값의 변화 폭이 증가해서 정확도가 감소하고, α의 크기가 너무 작은 경우에는 iteration횟수가 매우 많아져, 연산의 시간이 길어지므로 적당한 값을 사용해야 한다.
3. 위의 iteration을 수렴할 때까지 반복한다.
그럼 이제 위의 식을 정리해 보자. 우선, J(θ)를 θ에 관해 편미분의 결과는 다음과 같다.
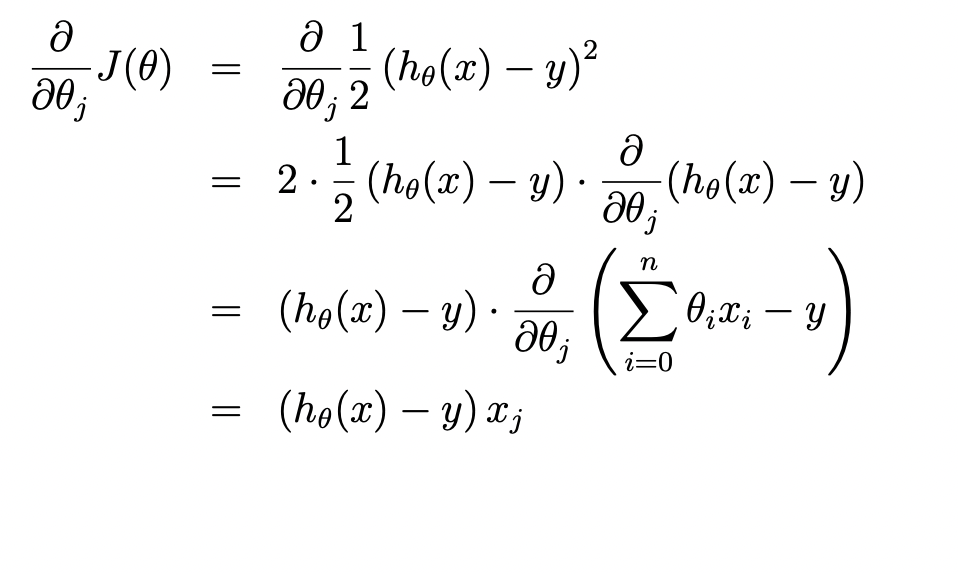
이를, 대입해서 최종식을 정리하면 다음과 같다.

이 식을, 수렴할 때까지 반복하면 된다.
한번 θ값을 업데이트할 때마다, 모든 m개의 training data들을 사용하게 된다.
(한 개의 단계에서는 모든 parameter들이 업데이트돼야 한다. 한 개씩 업데이트할 경우에는 원하는 최적값에 도달할 수 없음.)
그래서, 모든 데이터들을 사용한다는 의미에서 'batch' gradient descent라고도 한다. (batch는 데이터 더미? 를 의미하는 듯)
모든 데이터를 사용한다는 점에서 정확성의 장점도 있지만, 데이터의 양이 너무 큰 경우, 시간과 비용이 과하게 필요하다는 단점이 존재한다.
3번 목차에서는 이러한 단점의 대안으로 사용할 수 있는 'stochastic gradient descent' 알고리즘을 알아볼 것이다.
J(θ)의 꼴은 quadratic function(2차 함수)인 것을 알 수 있다. 따라서, 결괏값은 알고리즘의 최종 목표인 global optima에 도달한 게 된다.
(이차식이기에 local minima는 존재하지 않는다. global = local)
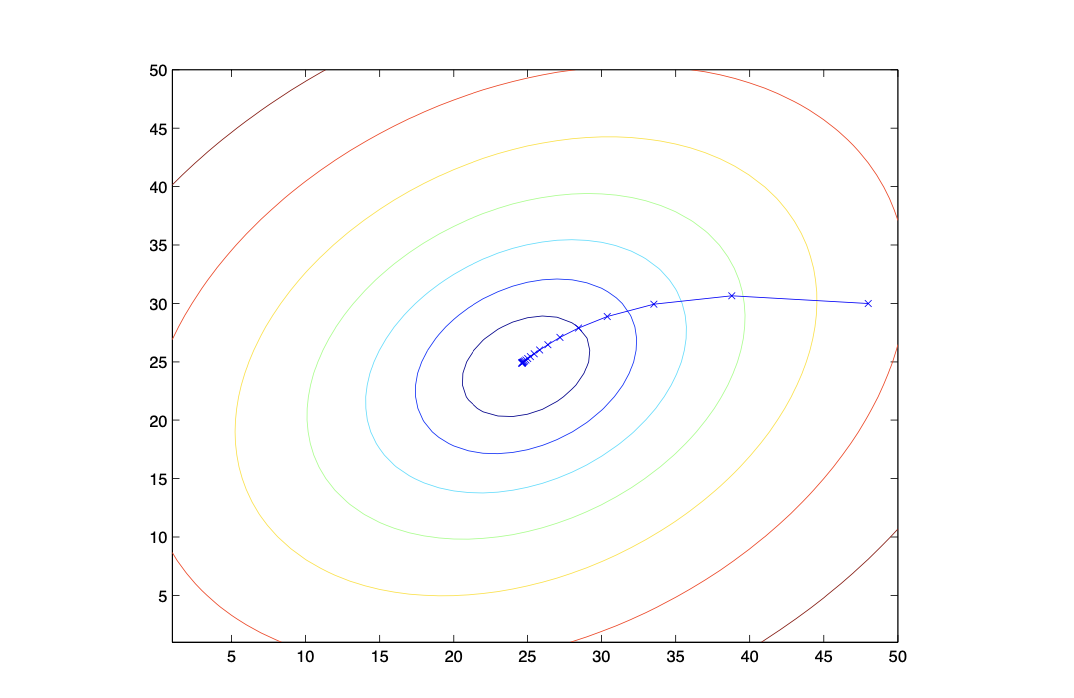
cf) 모든 gradient descent가 최적의 해인 global optima에 도달한다고는 보장할 수 없다.
위에서 알아본 Linear regression은 cost function이 least mean square형태로 convex quadratic function(이차 볼록)이어서 문제가 없지만 다음과 같이 복잡한 함수일 경우, θ을 업데이트 하는 과정에서 local optima나 saddle point에 빠질 경우, 우리가 원하는 global optima에 도달할 수 없다.

3. Stochastic Gradient Descent (확률적 경사 하강법)
batch gradeint descent처럼 모든 dataset를 한 번에 사용하는 대신, 하나의 data를 한 번씩 사용해서 θ를 없데이트 해주는 방식이다. data가 아주 클 때 batch보다 속도가 빨라서 사용하기 좋다.

이렇게 한개씩 사용할 경우, θ는 절대로 global optima로 수렴하지는 않는다. 충분한 양의 데이터로 계산을 할 경우, θ값은 최적의 값 주위에서 진동할 것이다. 이러한 부정확한 값을 사용해도 될 것인가 의구심이 생기겠지만, 대부분의 실험에서는, 최솟값 주위에서 진동하고 있는 이 값은 충분한 의미가 있다.

4. Normal Equation (정규 방정식)
위에서는 iteration을 통해 cost function을 최소화하는 방법을 알아보았다.
마지막 목차에서는 iteration을 사용하지 않고 J(θ)의 최소화를 explicit method로 해결해보자.
참고로 normal equation은 오직 linear regression problem에서만 가능하다.
cf) explicit method VS implicit method
영문 교과서를 보면 항상 explicit, implicit라는 용어가 나온다. 학교 다닐 때는 귀찮아서 그냥 넘어갔지만 자세한 차이를 알아보자.
explicit method(양해법) : 현재의 상태로부터 미래의 상태를 계산하는 방법.
implicit method(음해법) : 현재와 미래의 시간의 시스템의 상태로부터 미래의 상태를 계산하는 방법.
즉, explicit은

처럼 우항에서 n과 관련된 변수를 알면 좌항의 n+1 변수를 알 수 있는 것이고,
implicit은

우항에도 n+1과 관련된 변수가 섞여 있어, 재귀식을 풀어서 n+1 상태를 구하는 것이다.
프로그래밍의 관점에서 본다면, explicit은 상대적으로 계산이 쉽고 시간이 적게 걸리지만, 안정성이 떨어지고,
implicit은 반대로 계산이 오래걸리지만, 안정성이 높다는 장점이 있다.
from : https://en.wikipedia.org/wiki/Explicit_and_implicit_methods
Explicit and implicit methods - Wikipedia
From Wikipedia, the free encyclopedia Approaches for approximating solutions to differential equations Explicit and implicit methods are approaches used in numerical analysis for obtaining numerical approximations to the solutions of time-dependent ordinar
en.wikipedia.org
이제 다시 돌아와서, 'normal equation'을 알아보자. 이번 알고리즘에서는 J(θ)을 직접 θ에 관해서 미분을 해서 0인 지점을 찾는다. 따라서, 행렬과 관련된 미분이 많이 등장하는데, 익숙지 않아서 너무 어려웠다.
(관련된 수학적 내용은 따로 공부해서 정리해야 될 듯.. 지금은 식정도만 이해할 정도로만 공부해야지.)
우선 J(θ)를 다시 살펴보자.
여기서 input으로 받는 θ는 사실 vector로 n+1 차원 이다. J(θ)를 θ로 미분하는 것은 scalar을 vetor로 미분하는 것이 되므로, 다음과 같은 기호를 사용해서 미분식을 표현할 수 있다. column vector 형태로 표현을 하는 게 일반적이다.
위의 식을 계산하는 과정을 알아보자.
우선, training data set의 feature와 label을 다음과 같이 column vector 형태로 표현한다.

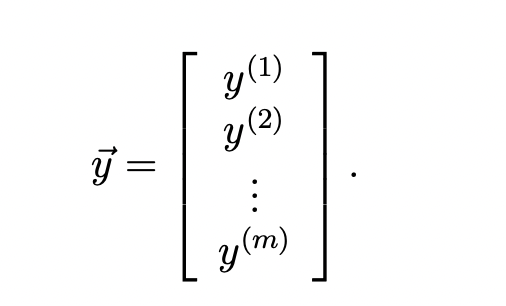
그 후, 다음과 같이 J(θ)를 변형시킬 수 있다.

이렇게 구한 θ값이 J(θ)를 최소화 해주는 값이다.
단, 조심해야할 점은 X 행렬의 역행렬 여부이다. X가 non-invertible 일 경우에는, 역행렬이 존재하지 않아서 구할 수가 없게 된다. 이 경우는, 중복되는 feature(연관성이 있는)이 존재하는 경우이기에, training data set을 다시 한번 확인해주어야 한다.
'Machine Learning' 카테고리의 다른 글
| [ML] Stanford cs229 ML Course Lecture 3 (0) | 2024.05.03 |
|---|---|
| [ML] Stanford cs229 ML Course Lecture 1 (0) | 2024.04.23 |

